We evaluate CPUs, GPUs and other AI accelerators using AIBench. BenchCouncil will publish the performance numbers periodically, more intelligent chips and accelerators will be evaluated. BenchCouncil welcomes everyone join the benchmarking and submit their results who is interested in the performance of AI systems and architectures.
Methodology
Our balanced AI benchmarking methodology consists of
five essential parts as follows.
- Performing a detailed survey of the most important domain
rather than a rough survey of a variety of domains.
As it is impossible to investigate all AI domains, we single out the most important AI domain–Internet services for the detailed survey with seventeen prominent industry partners. -
Include as most as possible representative benchmarks.
We believe the prohibitive cost of training a model to a state-of-the-art quality cannot justify including only a few AI benchmarks. Instead, using only a few AI component benchmarks may lead to error-prone design: over-optimization for some specific workloads or benchmarketing. For Internet services, we identify and include as most as possible representative AI tasks, models and data sets into the benchmark suite, so as to guarantee the representativeness and diversity of the benchmarks. This strategy is also witnessed by the past successful benchmark practice. Actually, the cost of execution time for other benchmarks like HPC, SPECCPU on simulators, is also prohibitively costly. However, the representativeness and coverage of a widely accepted benchmark suite are paramount important. For example, SPECCPU 2017 contains 43 benchmarks. The other examples include PARSEC3.0(30), TPC-DS (99). -
Keep the benchmark subset to a minimum.
We choose a minimum AI component benchmark subset according to the criteria: diversity of model complexity, computational cost, convergence rate, repeatability, and having the widely-accepted metrics or not. Meanwhile, we quantify the performance relationships between the full benchmark suite and its subset. Using the subset for ranking is also witnessed by the past practice. For example, Top500-a super computer ranking– only reports HPL and HPCG –two benchmarks out of 20+ representative HPC benchmarks like HPCC, NPB. -
Consider the comprehensive benchmarks and its subset as
two indispensable parts.
Different stages have conflicting benchmarking requirements. The initial design inputs to a new system/architecture need comprehensive workload characterization. For earlierstage evaluations of a new system or architecture, which even adopts simulation-based methods, heavy benchmarking is a big burden, thus, concise, portable, and lightweight benchmarks are of great significance. While later-stage evaluations of a new architecture or system or purchasing an commercial offthe-shelf ones needs detailed evaluation using comprehensive benchmarks to avoid error-prone design or benchmarketing. For initial design inputs, we perform detailed workload characterization. For later-stage evaluations of or purchasing a new system/architecture, we run the full benchmarks or selectively run some benchmarks to quickly locate the bottlenecks. For earlier-stage evaluations of a new system/architecture or ranking commercial off-the-shelf systems/architectures, we run an affordable subset. -
Layered Benchmarking Rules.
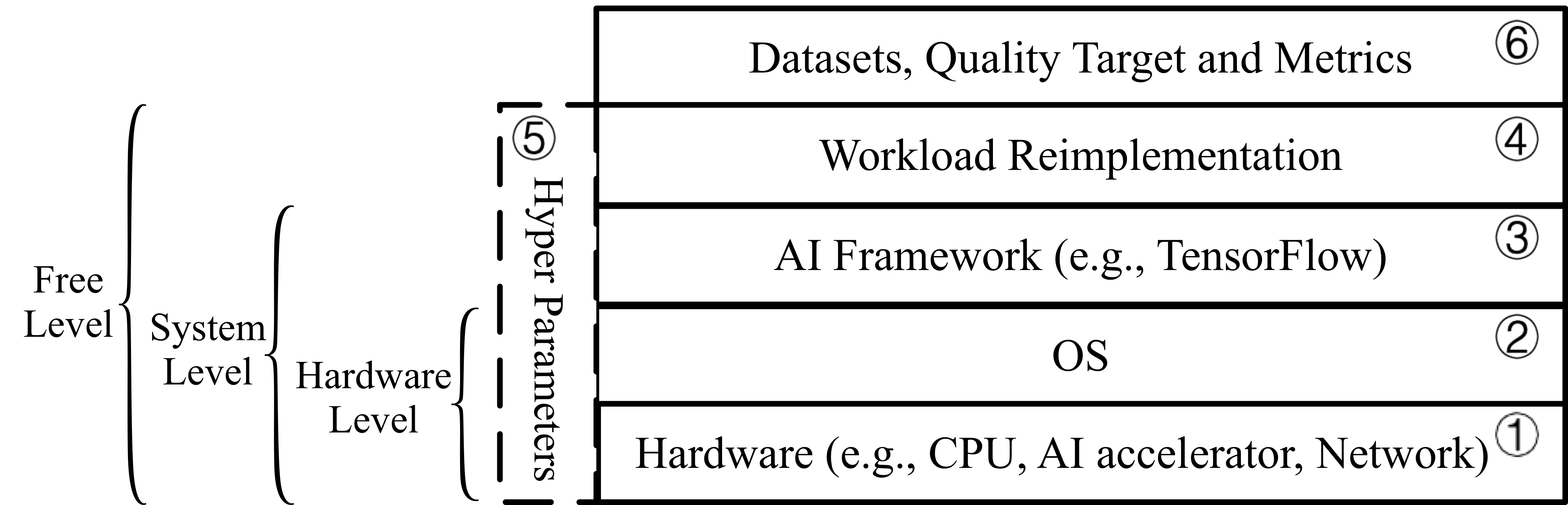
We define six benchmarking layers and corresponding rules, as illustrated in Fig. 1. In the hardware layer, the hardware configurations are allowed to be adjusted. OS layer represents the OS configurations or compiler options can be optimized. AI Framework layer means the AI framework can be changed. Workload re-implementation layer indicates that the re-implementation is allowed, however, it should be mathematical equivalence with the reference implementation. Hyper parameter layer defines the rules for hyper-parameter settings, including batchsize, learning rate, and the other hyper-parameters. To be specific, batchsize is allowed to be changed so as to fully utilize the hardware resources. Datasets and metrics layer specify the data input and evaluation metric, and cannot be modified. According to the above six layers, we define three-level benchmarking, including hardware, system, and free levels, as illustrated in Fig. 1. Hardware Level. This level allows the modifications of hardware, OS, and hyper-parameter layers, with the other layers unchanged. System Level. This level allows the modifications of hardware, OS, AI framework, and hyper-parameter layers, while the others are fixed. Note that for both hardware level and system level, only batchsize and learning rate are allowed to be changed, while the other hyper-parameters need to be the same with the reference implementation. Free Level. This level allows the modifications of all layers except for the datasets and metrics layer. Note that all the hyper-parameters are allowed to be changed.
AIBench Training Subset
Selection
- Reflecting diverse model complexity, computational cost,
and convergent rate.
Specifically, we intend to choose the benchmarks that cover different aspects as much as possible. For example, the subset should cover a wide range of the number of FLOPs, learnable parameters, convergent rate. - Run-to-run variation.
Repeatability is an important selection criteria of the subset. To avoid too much run-to-run variation, we choose the benchmarks with variance under 2%. - Widely accepted evaluation metrics.
A benchmark should have widely accepted performance metrics, so that runs from different users have consistent termination conditions. So we exclude the GAN-based models.
Finally, We include three benchmarks
into the subset: Image Classification, Object Detection, and
Learning-to-Rank. To satisfy the first criterion, they cover
different ranges of numbers in terms of FLOPs and learnable
parameters (both small for Learning-to-Rank, medium for
Image Classification, and large for Object Detection), and
different convergent rates (small epochs for Object Detection,
medium for Learning-to-Rank, and large for Image Classification). As for the second
criterion, three benchmarks have
the least run-to-run variation, 1.12% for Image Classification,
1.9% for Learning-to-Rank, and 0% for Object Detection.
In addition, they have widely accepted evaluation metrics–
accuracy for Image Classification, precision for Learning-toRank, and mAP for Object
Detection.
Futher, We use the metrics of model
complexity (parameter size), computational cost (FLOPs) and
convergent rate (number of epochs to the convergent quality)
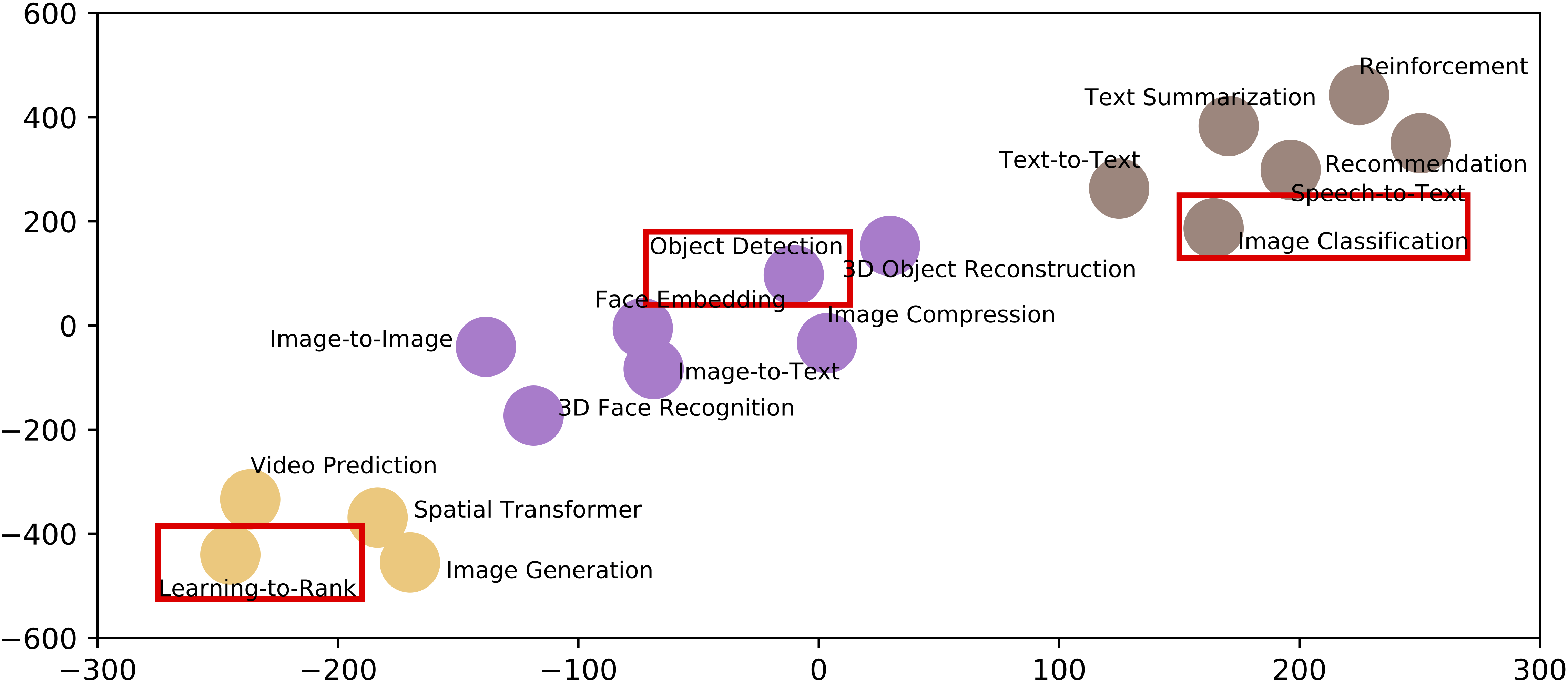
and perform K-means clustering on all seventeen component
benchmarks and subset of AIBench, to explore their similarities. We further use T-SNE
for visualization, which
a dimension reduction technique to embed high-dimensional
data in a low-dimensional space for visualization. Fig. 2
shows the result. The x-axis and y-axis are the position of the
Euclidean space after using t-SNE to process the above three
metrics. We find that these seventeen benchmarks are clustered into three classes, and
the subset—Image Classification,
Learning-to-Rank, and Object Detection—are in three different clusters. The result
further demonstrates that our subset is a
minimum set to achieve the maximum representativeness and
diversity of seventeen component benchmarks. To a certain
degree, the performance of a benchmark in the subset has the
ability to estimate the performance of the other benchmarks
within in the same cluster.
Metrics
BenchCouncil reports performance number, performance & quality number
(time-to-quality), and energy consumption number (energy-to-quality) using AIBench.
- Time-to-quality Number of AIBench Training Subset.
As the training time to a state-of-the-art quality requires a lot of execution time, for performance & quality ranking, we only choose AIBench training subset for reducing the cost just like that the HPC Top500 ranking only reports three benchmarks. - Energy-to-quality Number of AIBench Training Subset.
As the training time to a state-of-the-art accuracy requires a lot of execution time, for energy ranking, we only choose AIBench training subset for reducing the cost just like that the HPC Top500 ranking only reports three benchmarks. - Throughput Number of full benchmarks of AIBench.
We evaluate CPUs, GPUs and other AI accelerators using the AIBench inference benchmark. We run the benchmarks using optimized parameter settings to achieve the quality of referenced paper and report the throughput performance.
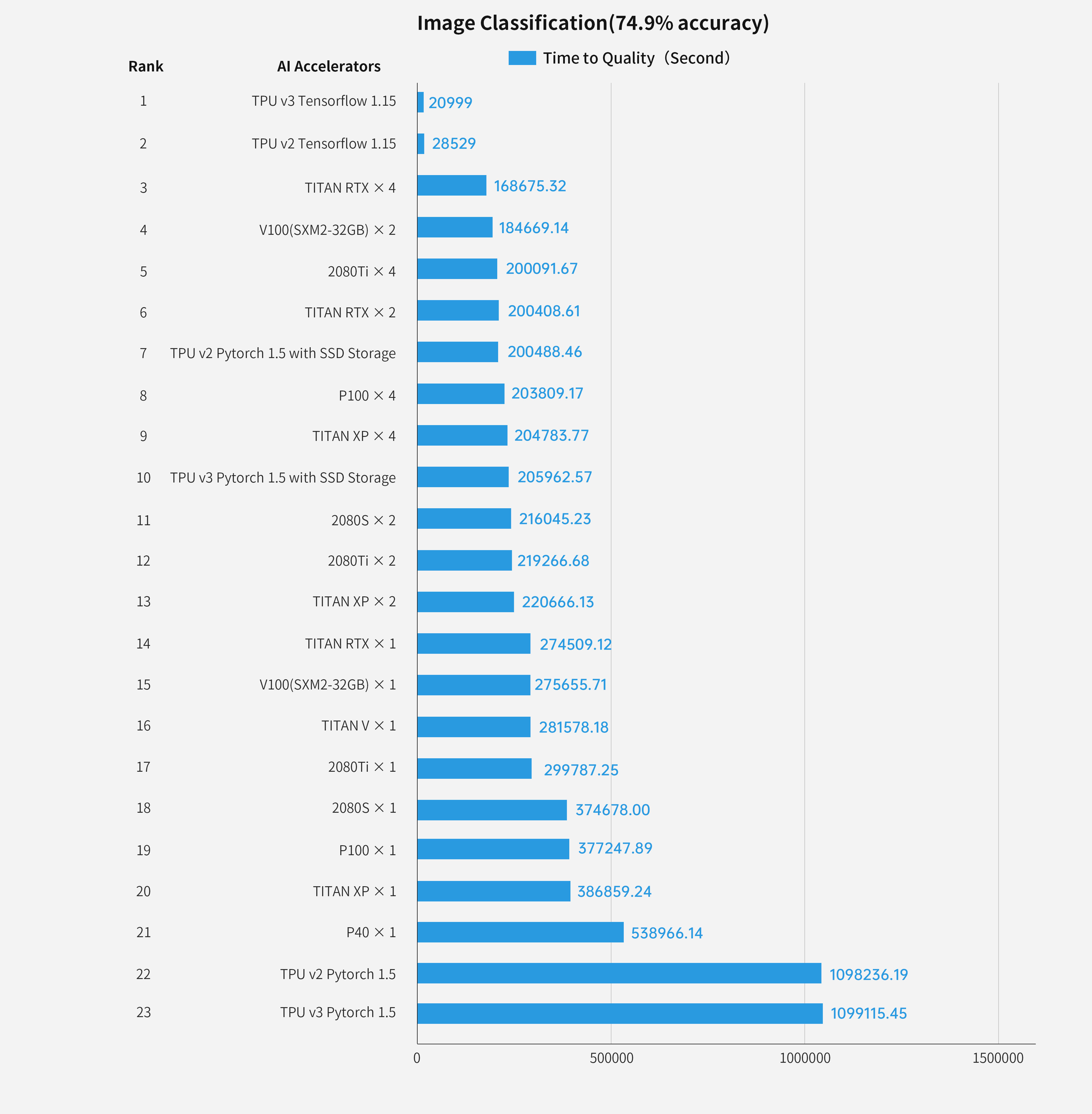
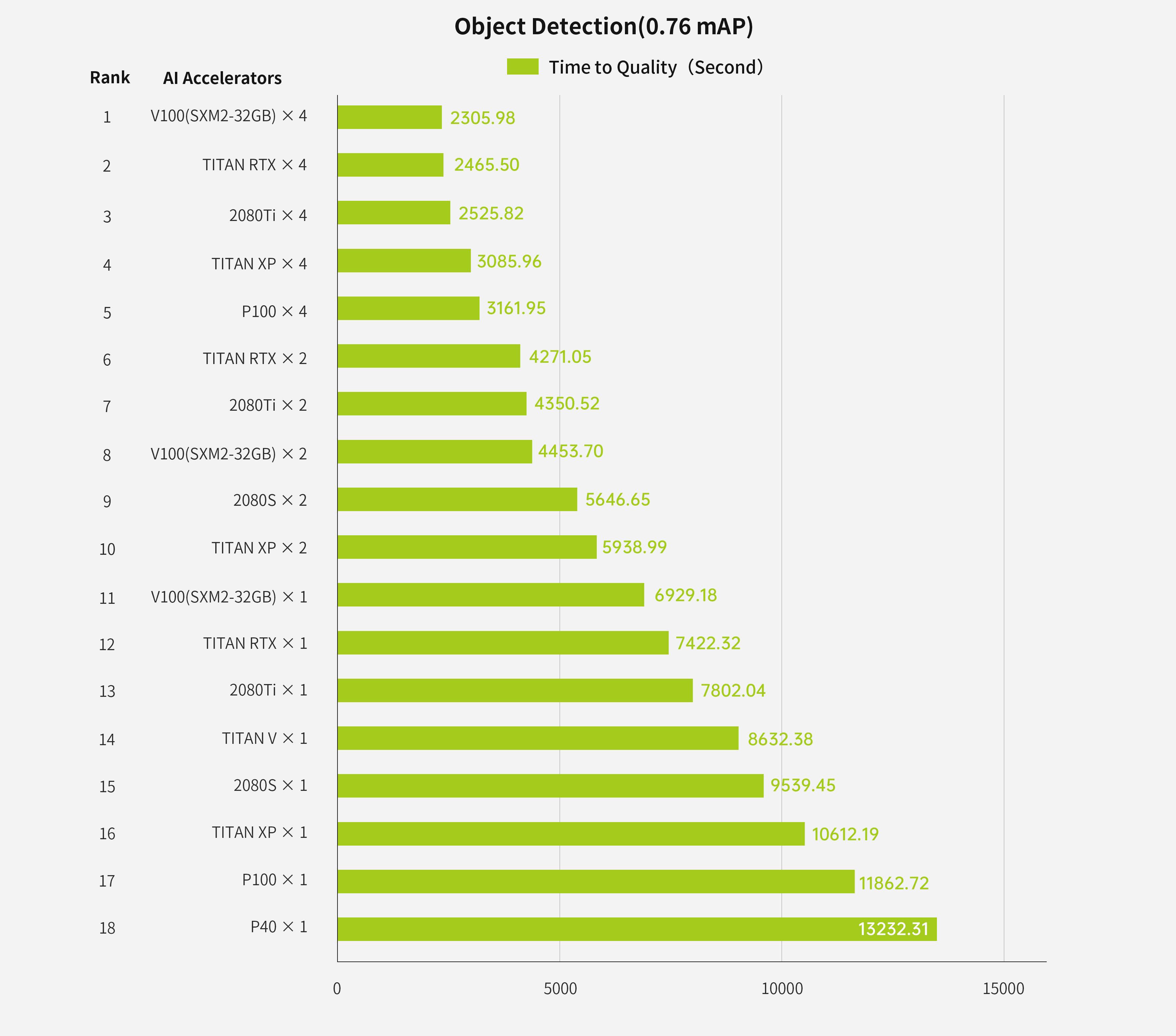
(1) Time-to-quality Numbers
Energy-to-quality number is available soon.
Inference Performance on Single GPU
To evaluate the inference performance of intelligent chips, we also evaluate the inference time on single GPU card. We find that the V100 also has the best inference performance, which performs 4 times better than the others at most. The inference performance of Titan XP is colse to V100 and has higher price–performance ratio. Likewise, the inference of partial AI workloads also have high memory requirements, such as object detection.
