Introduction
The recent years witness a trend of applying large-scale distributed deep learning algorithms in both business and scientific computing areas, whose goal is to speed up the training time to achieve a state-of-the-art quality. The HPC community feels a great interest in building the HPC AI systems that are dedicated to running those workloads. The HPC AI benchmarks accelerate the process. Unfortunately, benchmarking HPC AI systems at scale raises serious challenges. None of previous HPC AI benchmarks achieve the goal of being equivalent, relevant, representative, affordable, and repeatable.
HPC AI500 presents a comprehensive methodology, tools, Roofline performance models, and innovative metrics for benchmarking, optimizing, and ranking HPC AI systems. We abstract the HPC AI system into nine independent layers, and present explicit benchmarking rules and procedures to assure equivalence of each layer, repeatability, and replicability. On the basis of AIBench--by far the most comprehensive AI benchmarks suite, we present and build two HPC AI benchmarks from both business and scientific computing: Image Classification, and Extreme Weather Analytics, achieving both representativeness and affordability. To ranking the performance and energy-efficiency of HPC AI systems, we propose Valid FLOPS, and Valid FLOPS per watt, which impose a penalty on failing to achieve the target quality. We propose using convolution and GEMM--- the two most intensively-used kernel functions of AIBench to measure the upper bound performance of the HPC AI systems, and present HPC AI roofline models for guiding performance optimizations. The evaluations show our methodology, benchmarks, performance models, and metrics can measure, optimize, and rank the HPC AI systems in a scalable, simple, and affordable way.
Methodology
The goal of HPC AI500 methodology is to achieve being equivalent, relevant, representative,affordable, and repeatable.Equivalence
To perform fair benchmarking across different systems or the same system with different scale, we propose two approaches to assure the equivalence.
First, as shown in Figure 1, we abstract the system under test into nine independent layers, and put eachlayer under test while keeping the other layers intact unless otherwise stated.
Layer 1 is the hardware, including CPUs and networks. Layers 2, and 3 are the related system software, including the operating system (Layer 2), and the communication libraries (Layer 3). Layer 4 isthe AI accelerators, i.e., GPU, and libraries, i.e., CUDA and cuDNN. Layer 5 is the AI framework, such as TensorFlow and PyTorch . Layer 6 refers to programming model, including parallel mode(data parallelism or model parallelism), and synchronous or asynchronous training. Layer 7 refers to the workloads used in HPC AI500 V2.0 benchmark. Layer 8 refers to hyper-parameters policies or settings.Layer 9 refers to problem domain, including datasets, target quality, and epochs.
Second, for the sake of simpleness, we propose three high levels of benchmarking and put severalrelated layers together under test.
1) The hardware level. This high level is for benchmarking HPC AI hardware systems and their related system software (Layers 1, 2, 3, 4). In this context, the other layers should be kept intact unlessotherwise stated in the benchmarking rules. The benchmark users should compile the source code ofthe benchmark implementation, provided by the benchmark committee, on their hardware directly withallowed changes. Luo et al. [43] show that the same model on different frameworks has different accuracy.So in addition to the same data set, and AI model, we mandate that the benchmark implementationsalso use the same AI framework. The benchmark users can change hardware, OS, compiler settings,communication libraries. For the other layers, the benchmark users can only change parallel modes inLayer 6 or tune learning rate policies and batchsize settings in Layer 8. It is the benchmark committee’duty to assure the equivalence of Layers 6, 7, 8, 9 across different benchmark implementations upon theusers’ requests.
(2) The system level. Because of the portability cost, some benchmark users may opt for one specific AI framework without the support of the other, so specifying a fixed framework has a limited purpose. Soin the system level, we put the hardware system in addition to the AI framework under the test (Layers1, 2, 3, 4, and 5), which we call the system level. We mandate that the benchmark implementations use the same data set, and AI model. In addition to the changes allowed in the hardware level, the users areallowed to re-implement the algorithms on different or even customized AI framework (Layer 5). Theother layers should be kept intact unless otherwise stated in the benchmarking rules.The benchmark committee or an independent group need double-check the equivalence of Layers 6, 7,8, 9 between the two benchmark implementations.
(3) The free level. In this high level, the specification of an AI task is stated in a paper-and-pencilmanner separating from its specific implementation. That is to say, the same data set, target quality, andtraining epochs are defined in Layer 9 while the other layers are open for optimizations. The emphasis isadvancing the state-of-the-art of software and hardware co-design, so the benchmark users can change any layers from Layer 1 to Layer 8 while keeping Layer 9 intact. Meanwhile, the benchmark users are encouraged to disclose the details
Figure 1: The equivalent perspective of HPC AI500 V2.0 Methodology.

Representative vs. Affordable
We choose the AIBench subset as the HPC AI500 V2.0 candidate benchmarks for implementingscalable HPC AI benchmark tools
First of all, AIBench [10] is by far the most representative and comprehensive AI benchmark suite.It contains seventeen representative AI tasks. These workloads are diverse in terms of model complexity,computational cost, and convergent rate, computation and memory access patterns, hotspot functions, andother micro-architecture characteristics
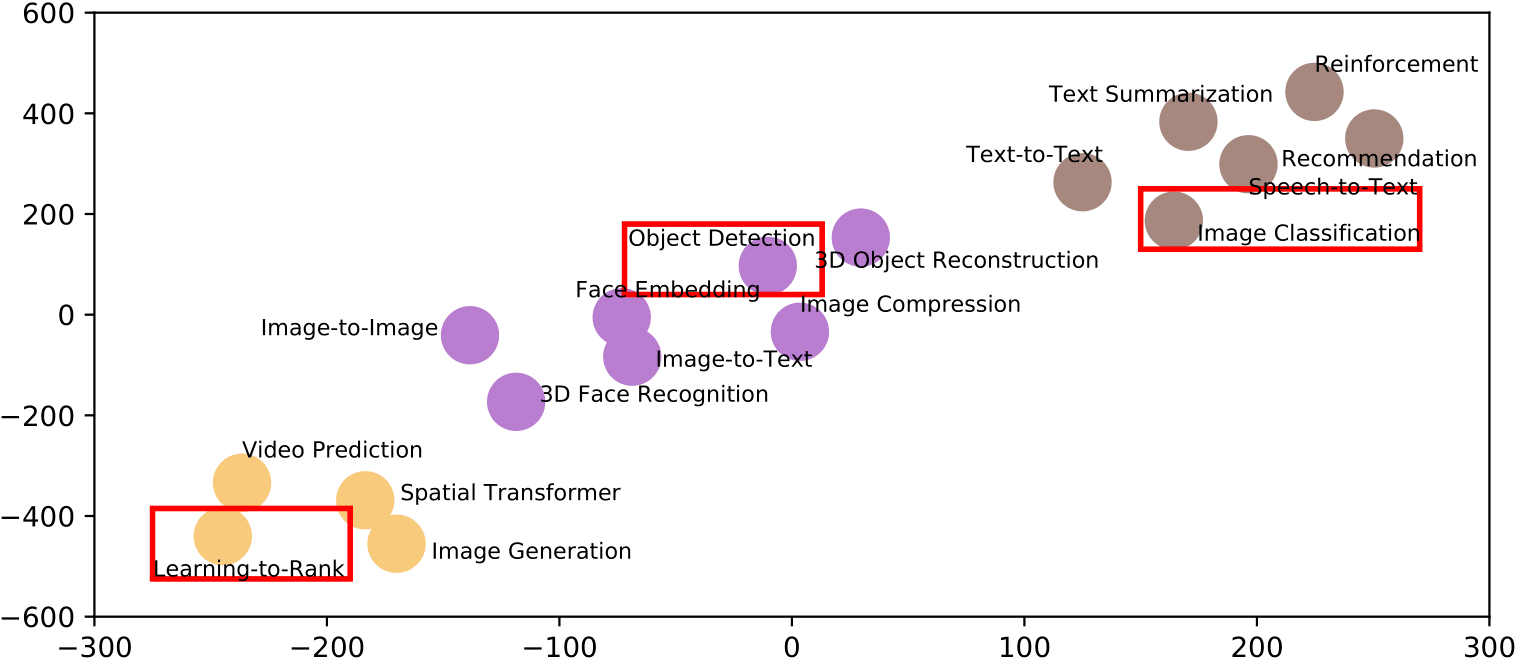
Second, for affordability, AIBench carefully selected a minimum subset from the seventeen AI tasks from perspectives of model complexity, computational cost, convergent rate, run-to-run variation,and having widely accepted evaluation metrics or not. As shown in Figure 2, the AIBench subset includesthree AI tasks–Image Classification, Object Detection, and Learning to Rank.
At last, AIBench systematically quantify the run-to-run variation of seventeen AI tasks of AIBench in terms of the standard deviation to the mean of the training epochs to achieve a convergent quality.The variation of image classification, object detection, and learning ranking is 1.12%, 0%, and 1.90%,respectively, and they are the most repeatable benchmarks, which is the other reason for including theminto the subset.
Figure 2: The three subset of AIBench with respect to the full benchmarks. The clustering is based on thepatterns of computation and memory access of seventeen AIBench component benchmarks.
Repeatability and Replicability
We propose the benchmarking procedures forassuring repeatability and replicability. We adopt the definition similar to that of the Association for Computing Machinery. Different from reproducibility, which requires changes, repeatability andreplicability avoid changes.
Repeatability (same team): The benchmarking is performed on the same HPC AI system, usingthe same benchmark implementation under the same configurations, following the same benchmarking procedures, on multiple trials. The team should submit the raw data of all trials, including the average numbers in addition to itsvariations. The variation is measured in terms of the ratio of the standard deviation to the mean of the numbers of all trials. To mitigate the influence of stochastic of the AI algorithm, each benchmark should mandate theleast valid runs of benchmarking. The number of all trials should be more than the least valid runs ofbenchmarking.
Replicability (Different team): The replicability refers to that the other team verifies the bench-marking results on the same HPC AI system, using the same benchmark implementation under the same configurations, following the same benchmarking procedures, on multiple trials. For replicability, the benchmark committee or an independent group need verify the numbers onthe same system, and report the raw data of all trials, including the average numbers in addition to itsvariation
Specification
The HPC AI500 V2.0 specification and associated metrics are described in section Specification.
Ranking
HPC AI500 Ranking is available from Ranking.
Contributors
Prof. Jianfeng Zhan, ICT, Chinese Academy of Sciences, and BenchCouncil
Zihan Jiang, ICT, Chinese Academy of Sciences
Dr. Wanling Gao, ICT, Chinese Academy of Sciences
Dr. Lei Wang, ICT, Chinese Academy of Sciences
Xingwang Xiong, ICT, Chinese Academy of Sciences
Yuchen Zhang, State University of New York at Buffalo
Xu Wen, ICT, Chinese Academy of Sciences
Chunjie Luo, ICT, Chinese Academy of Sciences
Hainan Ye, BenchCouncil and Beijing Academy of Frontier
Sciences and Teconology
Xiaoyi Lu, The Ohio State University
Yunquan Zhang, National Supercomputing Center in Jinan, China
Shengzhong Feng, National Supercomputing Center in Shenzhen, China
Kenli Li, National Supercomputing
Center in Changsha, China
Weijia Xu, Texas Advanced Computing Center, The Texas University at Austin
Supports







License
AIBench is available for researchers interested in AI. Software components of AIBench are all available as open-source software and governed by their own licensing terms. Researchers intending to use AIBench are required to fully understand and abide by the licensing terms of the various components. AIBench is open-source under the Apache License, Version 2.0. Please use all files in compliance with the License. Our AIBench Software components are all available as open-source software and governed by their own licensing terms. If you want to use our AIBench you must understand and comply with their licenses. Software developed externally (not by AIBench group)
- TensorFlow: https://www.tensorflow.org
- PyTorch: https://pytorch.org/
- Caffe2: http://caffe2.ai
- Redistribution of source code must comply with the license and notice disclaimers
- Redistribution in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimers in the documentation and/or other materials provided by the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS “AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE ICT CHINESE ACADEMY OF SCIENCES BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.