Summary
Real-world application scenarios like modern Internet services consist of diversity of AI and non-AI modules with very long and complex execution paths. Worst of all, the real-world data sets, workloads or even AI models are hidden within the Internet service giant' datacenters, which further exaggerates the benchmarking challenges. In addition, modern Internet service workloads dwarf the traditional ones in terms of code size, deployment scale, and execution path, and hence raise serious benchmarking challenges. On one hand, the hardware and software designers should consider the overall system effects from the perspective of an application scenario. Using component or micro AI benchmarks alone can lead to error-prone conclusions, as some mixed precision optimizations may improve the throughput while significantly increase time-to-quality. The overall system tail latency deteriorates even hundreds times comparing to a single AI component tail latency according to our experimental results, which can not be predicted by a state-of-the-art statistical model.
On the other hand, it is usually difficult to justify porting a real-world application to a new computer system or architecture simply to obtain a benchmark number. For hardware designers, a real-world application is too huge to run on the simulators, even if we can build it from scratch. Moreover, as a benchmark, a full-scale real-world application raises the repeatability challenge in terms of measurement errors and the fairness challenge in terms of assuring the equivalence of the benchmark implementations across different systems. After gaining full knowledge of overall critical information, micro and component benchmarks are still a necessary part of the evaluation.
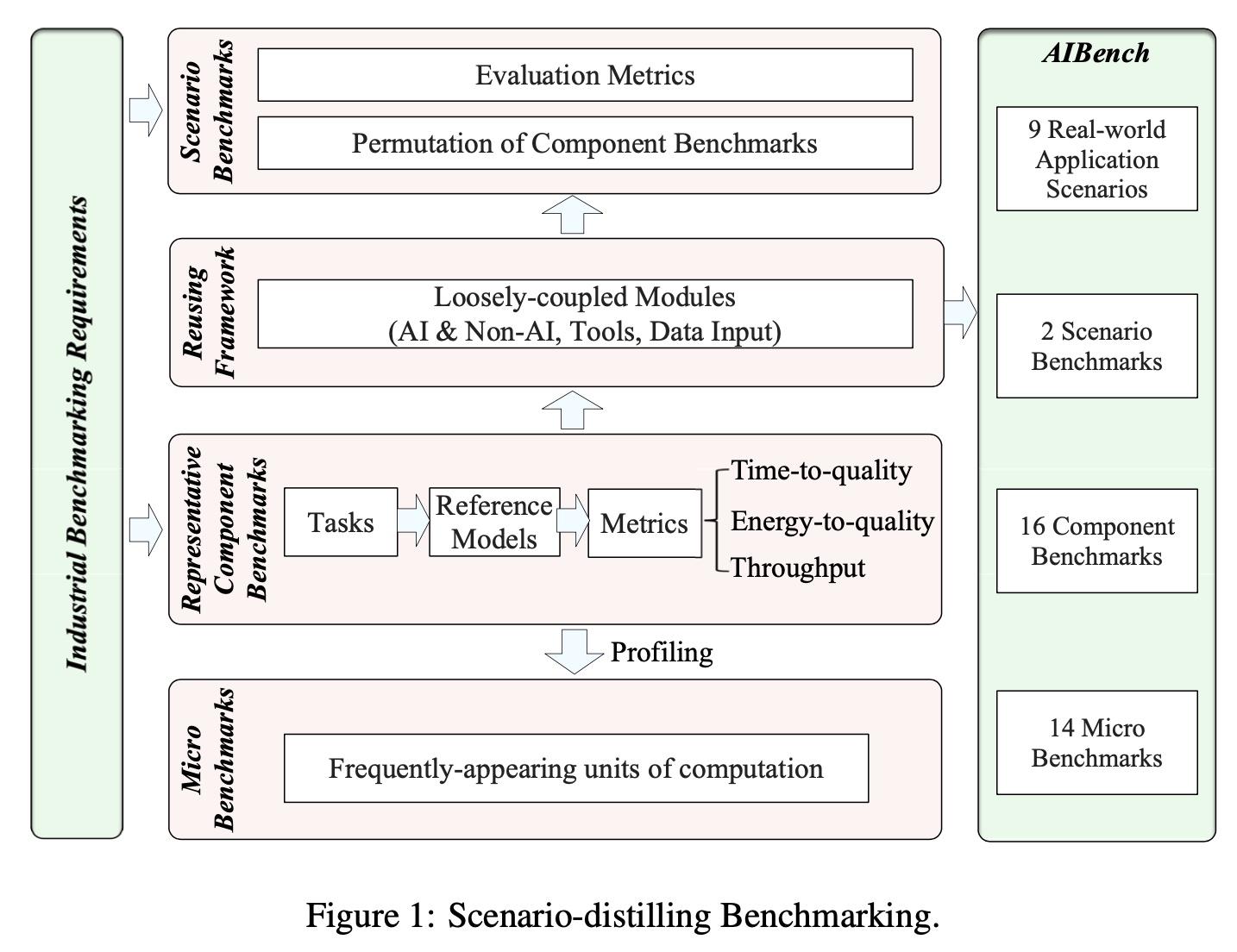
AIBench Scenario adopts a scenario-distilling AI benchmarking methodology. Instead of using real-world applications, we propose the permutations of essential AI and non-AI tasks as a scenario-distilling benchmark (in short, scenario benchmark). Each scenario benchmark is a distillation of the essential attributes of an industry-scale application, and hence reduces the side effect of the latter’s complexity in terms of huge code size, extreme deployment scale, and complex execution paths. We consider scenario, component and micro benchmarks as three indispensable parts of a benchmark suite. A scenario benchmark lets software and hardware designers learn about the overall system information, and locates the primary component benchmarks–representative tasks with specified targets–which provide diverse computation and memory access patterns for the micro-architectural researchers. Finally, the code developers can zoom in on the hotspot functions of the micro benchmarks–frequently-appearing units of computation among diverse component benchmarks–for performance optimization.
AIBench Scenario is the first industry-scale scenario-distilling AI benchmark suite, joint with a lot of industry partners. First, we identify nine important real-world application scenarios and present a highly extensible, configurable, and flexible benchmark framework, containing multiple loosely coupled modules like data input, non-AI library, online inference, offline training and automatic deployment tool modules. The AIBench framework allows researchers to create scenario benchmarks by reusing the components commonly found in major application scenarios. Then we abstract and identify seventeen prominent AI related tasks and implement them as component benchmarks, including classification, image generation, text-to-text translation, image-to-text, image-to-image, speech-to-text, face embedding, 3D face recognition, object detection, video prediction, image compression, recommendation, 3D object reconstruction, text summarization, spatial transformer, learning to rank, and neural architecture search. We further profile and implement fourteen fundamental units of computation across different component benchmarks as the micro benchmarks. On the basis of the AIBench framework, we design and implement the two scenario-distilling Internet service AI benchmark with an underlying e-commerce searching business model and an online translation intelligence, respectively. The scenario benchmarks reuse several component benchmarks from the AIBench framework, receives the query requests and performs AI related and non-AI related tasks. The data maintains the real-world data characteristics through anonymization. Data generators are also provided to generate specified data scale, using several configurable parameters.
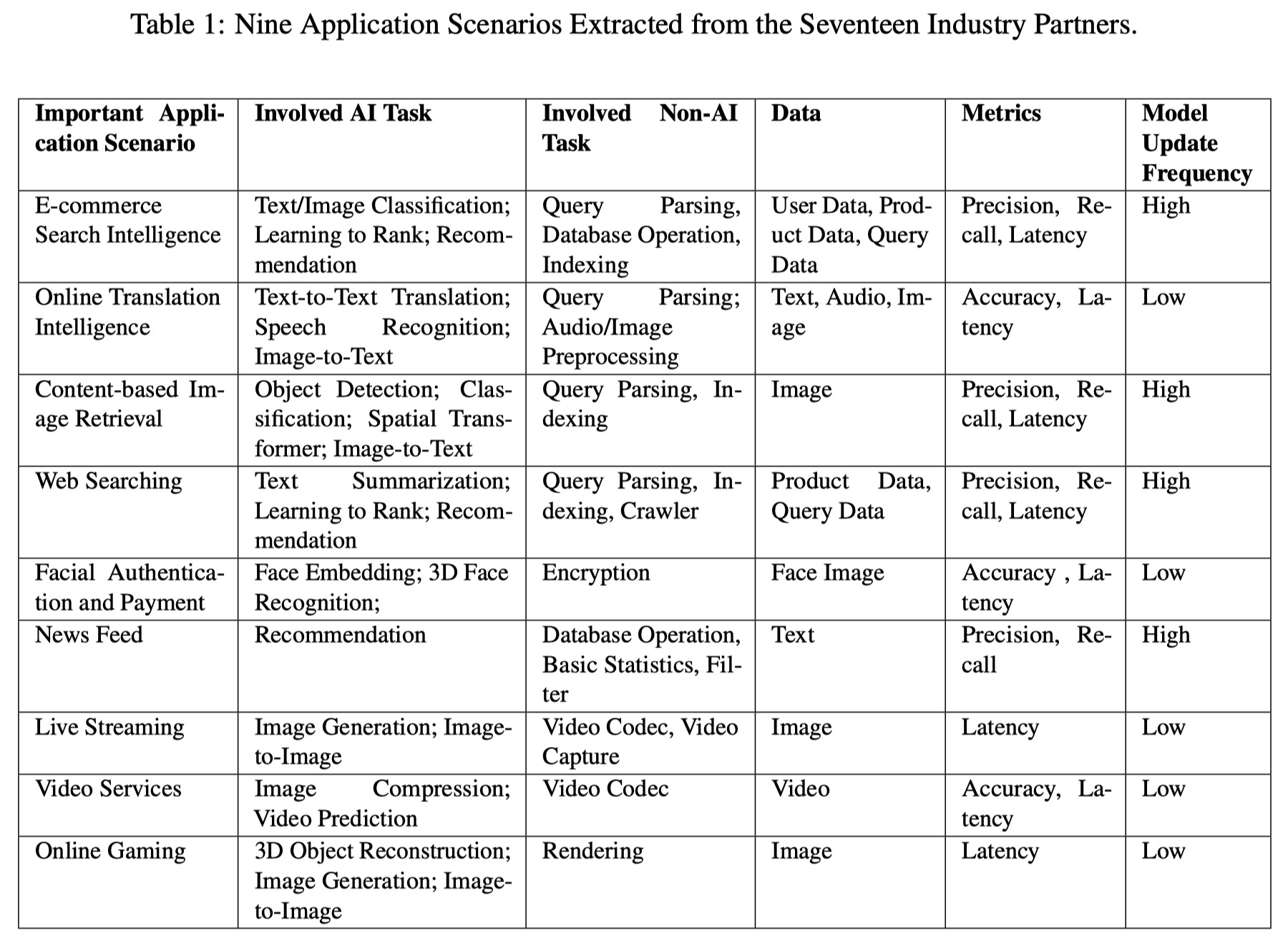
Nine Application Scenarios Extracted from the Seventeen Industry Partners
Collaborating with the seventeen industry partners whose domains include search engine, e-commerce, social network, news feed, video and etc, we extract typical real-world application scenarios from their products or services. A real-world application is complex, and we only distill the permutations of primary AI and non-AI tasks. Table 1 summarizes the list of important application scenarios. In general, a scenario benchmark concerns the overall system’s effects, including quality-ensured response latency, tail latency, and latency-bounded throughput. A quality-ensured performance example is a quality (e.g., accuracy) deviation from the target being within 2%. In general, each application scenario has its specific performance concerns. For example, several real-world applications require that the AI model is updated in a real time manner.
The Summary of Representative AI Tasks
To cover a wide spectrum of AI tasks, we thoroughly analyze the core scenarios among three primary Internet services, including search engine, social network, and e-commerce, as shown in Table 1. In total, we identify seventeen representative AI problem domains as follows.
- Image classification. This task is to extract different thematic classes within the input data like an image or a text file, which is a supervised learning problem to define a set of target classes and train a model to recognize. It is a typical task in Internet services or other application domains, and widely used in multiple scenarios, like category prediction and spam detection.
- Image generation. This task aims to provide an unsupervised learning problem to mimic the distribution of data and generate images. The typical scenario of this task includes image resolution enhancement, which can be used to generate high-resolution image.
- Text-to-Text translation. This task need to translate text from one language to another, which is the most important field of computational linguistics. It can be used to translate the search query intelligently and translate dialogue.
- Image-to-Text. This task is to generate the description of an image automatically. It can be used to generate image caption and recognize optical character within an image.
- Image-to-Image. This task is to convert an image from one representation of an image to another representation. It can be used to synthesize the images with different facial ages and simulate virtual makeup. Face aging can help search the facial images ranging different age stages.
- Speech recognition. This task is to recognize and translate the spoken language to text. This task is beneficial for voice search and voice dialogue translation.
- Face embedding. This task is to transform a facial image to a vector in embedding space. The typical scenarios of this task are facial similarity analysis and face recognition.
- 3D face recognition. This task is to recognize the 3D facial information from multiple images from different angles. This task mainly focuses on three-dimensional images and is beneficial to the facial similarity and facial authentication scenario.
- Object detection. This task is to detect the objects within an image. The typical scenarios are vertical search like contented-based image retrieval and video object detection.
- Recommendation. This task is to provide recommendations. This task is widely used for advertise recommendation, community recommendation, or product recommendation.
- Video prediction. This task is to predict the future video frames through predicting previous frames transformation. The typical scenarios are video compression and video encoding, for efficient video storage and transmission.
- Image compression. This task is to compress the images and reduce the redundancy. The task is important for Internet service in terms of data storage overhead and data transmission efficiency.
- 3D object reconstruction. This task is to predict and reconstruct 3D objects. The typical scenarios are maps search, light field rendering and virtual reality.
- Text summarization. This task is to generate the text summary, which is important for search results preview, headline generation, and keyword discovery.
- Spatial transformer. This task is to perform spatial transformations. An typical scenario of this task is space invariance image retrieval, so that the image can be retrieved even if the image is extremely stretched.
- Learning to rank. This task is to learn the attributes of searched content and rank the scores for the results, which is the key for searching service.
- Neural architecture search. This task is to automatically design neural networks.
AIBench Scenario Framework
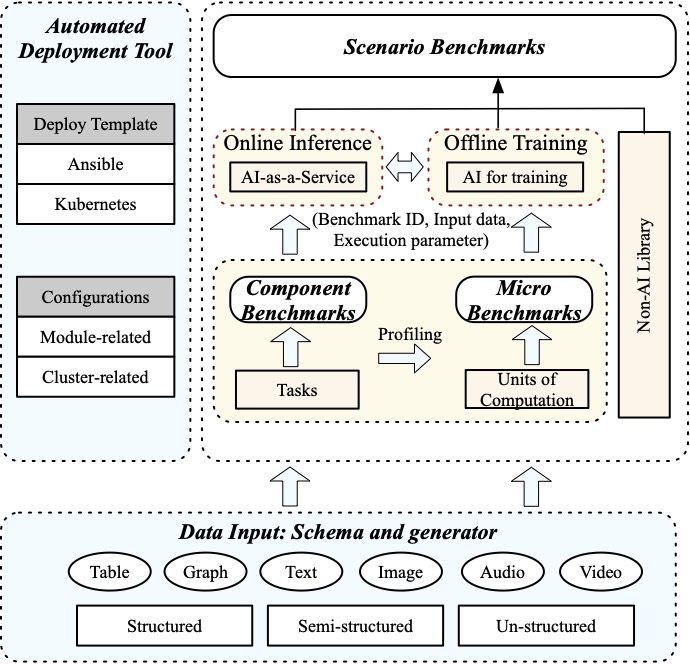
The AIBench Scenario framework provides a universal AI benchmark framework that is flexible and configurable, which is shown in Fig. 1. It provides loosely coupled modules that can be easily configured and extended to compose a scenario benchmark, including the data input, AI problem domain, online inference, offline training, and deployment tool modules.
The data input module is responsible to feed data into the other modules. It collects representative real-world data sets from not only the authoritative public websites but also our industry partners after anonymization. The data schema is designed to maintain the real-world data characteristics, so as to alleviate the confidential issue. Based on the data schema, a series of data generators are further provided to support large-scale data generation, like the user or product information. To cover a wide spectrum of data characteristics, we take diverse data types, e.g., structured, semi-structured, un-structured, and different data sources, e.g., table, graph, text, image, audio, video, into account. Our framework integrates various open-source data storage systems, and supports large-scale data generation and deployment.
The offline training and online inference modules are provided to construct a scenario benchmark. First, the offline training module chooses one or more component benchmarks, through specifying the required benchmark ID, input data, and execution parameters like batch size. Then the offline training module trains a model and provides the trained model to the online inference module. The online inference module loads the trained model onto the serving system, i.e., TensorFlow serving. Collaborating with the other non AI-related modules in the critical paths, a scenario benchmark is built.
To be easily deployed on a large-scale cluster, the framework provides deployment tools that contain two automated deployment templates using Ansible and Kubernetes, respectively. Among them, the Ansible templates support scalable deployment on physical machines or virtual machines, while the kubernetes templates are used to deploy on container clusters. A configuration file needs to be specified for installation and deployment, including module parameters like the chosen benchmark ID, input data, and the cluster parameters like nodes, memory, and network information.
Figure 1 AIBench Scenario Framework.
Micro, Component, Application Benchmarks in AIBench
AIBench provides a comprehensive AI benchmark suite, including 2 scenario benchmarks: E-commerce Search Intelligence and Online Translation Intelligence, 17 component benchmarks, and 14 micro benchmarks. To cover a full spectrum of data characteristics, AIBench collects 17 representative data sets for datacenter AI benchmarks. The benchmarks are implemented not only based on main-stream deep learning frameworks like TensorFlow and PyTorch, but also based on traditional programming model like Pthreads, to conduct an apple-to-apple comparison.
Scenario Benchmarks
E-commerce Search Intelligence
On the basis of the reusing framework, we implement E-commerce Intelligence. This benchmark models the complete use case of a realistic E-commerce search augmented with AI, covering both text and image searching. E-commerce Intelligence consists of four subsystems: Online Server, Offline Analyzer, Query Generator, and Data Storage.
Online Translation Intelligence
To illustrate the usability and composability of our reusing framework, we build another scenario benchmark—Online Translation Intelligence (in short, Translation Intelligence). This benchmark models the complete use case of a realistic online translation scenario, including not only text-to-text translation but also audio translation and image-to-text conversion and translation. Online Translation Intelligence consists of four subsystems: Online Server, Offline Analyzer, Query Generator, and Data Storage.
Table 2. Component Benchmark
|
No. |
Component Benchmark |
Algorithm |
Data Set |
Software Stack |
|
DC-AI-C1 |
Image classification |
ResNet50 |
ImageNet |
TensorFlow, PyTorch |
|
DC-AI-C2 |
Image generation |
WassersteinGAN |
LSUN |
TensorFlow, PyTorch |
|
DC-AI-C3 |
Text-to-Text trans- lation |
Transformer |
WMT English-German |
TensorFlow, PyTorch |
|
DC-AI-C4 |
Image-to-Text |
Neural Image Caption Model |
Microsoft COCO |
TensorFlow, PyTorch |
|
DC-AI-C5 |
Image-to-Image |
CycleGAN |
Cityscapes |
TensorFlow, PyTorch |
|
DC-AI-C6 |
Speech-to-Text |
DeepSpeech2 |
Librispeech |
TensorFlow, PyTorch |
|
DC-AI-C7 |
Face embedding |
Facenet |
LFW, VGGFace2 |
TensorFlow, PyTorch |
|
DC-AI-C8 |
3D Face Recognition |
3D face models |
77,715 samples from 253 face IDs |
TensorFlow, PyTorch |
|
DC-AI-C9 |
Object detection |
Faster R-CNN |
Microsoft COCO |
TensorFlow, PyTorch |
|
DC-AI-C10 |
Recommendation |
Collaborative filtering |
MovieLens |
TensorFlow, PyTorch |
|
DC-AI-C11 |
Video prediction |
Motion-Focused predictive models |
Robot pushing dataset |
TensorFlow, PyTorch |
|
DC-AI-C12 |
Image compression |
Recurrent neural network |
ImageNet |
TensorFlow, PyTorch |
|
DC-AI-C13 |
3D ob ject reconstruction |
Convolutional encoder-decoder network |
ShapeNet Dataset |
TensorFlow, PyTorch |
|
DC-AI-C14 |
Text summarization |
Sequence-to-sequence model |
Gigaword dataset |
TensorFlow, PyTorch |
|
DC-AI-C15 |
Spatial transformer |
Spatial transformer networks |
MNIST |
TensorFlow, PyTorch |
|
DC-AI-C16 |
Learning to rank |
Ranking distillation |
Gowalla |
TensorFlow, PyTorch |
|
DC-AI-C17 |
Neural architecture search |
Efficient neural architecture search |
PTB |
TensorFlow, PyTorch |
Table 3. Micro Benchmark
|
No. |
Micro Benchmark |
Involved Data Motif |
Data Set |
Software Stack |
|
DC-AI-M1 |
Convolution |
Transform |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M2 |
Fully Connected |
Matrix |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M3 |
Relu |
Logic |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M4 |
Sigmoid |
Matrix |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M5 |
Tanh |
Matrix |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M6 |
MaxPooling |
Sampling |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M7 |
AvgPooling |
Sampling |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M8 |
CosineNorm |
Basic Statistics |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M9 |
BatchNorm |
Basic Statistics |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M10 |
Dropout |
Sampling |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M11 |
Element-wise multiply |
Matrix |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M12 |
Softmax |
Matrix |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M13 |
Memcpy |
Matrix |
Cifar, ImageNet |
TensorFlow, Ptheads |
|
DC-AI-M14 |
Data arrangement |
Matrix |
Cifar, ImageNet |
TensorFlow, Ptheads |
Metrics
AIBench focuses on a series of metrics covering accuracy, performance, and energy consumption, which are major industry concerns. The metrics for online inference contains query response latency, tail latency, and throughput from performance aspect, inference accuracy, and inference energy consumption.
The metrics for offline training contains the samples processed per second, the wall clock time to train the specific epochs, the wall clock time to train a model achieving a target accuracy, and the energy consumption to train a model achieving a target accuracy.
Data Model
To cover a diversity of data sets from various applications, we collect 17 representative data sets, including ImageNet, Cifar, LSUN, WMT English-German, Cityscapes, LibriSpeech, Microsoft COCO data set, LFW, VGGFace2, Robot pushing data set, MovieLens data set, ShapeNet data set, Gigaword data set, MNIST data set, Gowalla data set, PTB data set, and the 3D face recognition data set from our industry partner.
Contributors
Prof. Jianfeng Zhan, ICT, Chinese Academy of Sciences, and BenchCouncil
Dr. Wanling Gao, ICT, Chinese Academy of Sciences
Fei Tang, ICT, Chinese Academy of Sciences
Dr. Lei Wang, ICT, Chinese Academy of Sciences
Xu Wen, ICT, Chinese Academy of Sciences
Chuanxin Lan, ICT, Chinese Academy of Sciences
Chunjie Luo, ICT, Chinese Academy of Sciences
Yunyou Huang, ICT, Chinese Academy of Sciences
Dr. Chen Zheng, ICT, Chinese Academy of Sciences, and BenchCouncil
Dr. Zheng Cao, Alibaba
Hainan Ye, Beijing Academy of Frontier Sciences and BenchCouncil
Jiahui Dai, Beijing Academy of Frontier Sciences and BenchCouncil
Daoyi Zheng, Baidu
Haoning Tang, Tencent
Kunlin Zhan, 58.com
Biao Wang, NetEase
Defei Kong, ByteDance
Tong Wu, China National Institute of Metrology
Minghe Yu, Zhihu
Chongkang Tan, Lenovo
Huan Li, Paypal
Dr. Xinhui Tian, Moqi
Yatao Li, Microsoft Research Asia
Dr. Gang Lu, Huawei
Junchao Shao, JD.com
Zhenyu Wang, CloudTa
Xiaoyu Wang, Intellifusion
Ranking
AIBench results are released.
License
AIBench is available for researchers interested in AI. Software components of AIBench are all available as open-source software and governed by their own licensing terms. Researchers intending to use AIBench are required to fully understand and abide by the licensing terms of the various components. AIBench is open-source under the Apache License, Version 2.0. Please use all files in compliance with the License. Our AIBench Software components are all available as open-source software and governed by their own licensing terms. If you want to use our AIBench you must understand and comply with their licenses. Software developed externally (not by AIBench group)
- TensorFlow: https://www.tensorflow.org
- PyTorch: https://pytorch.org/
- Caffe2: http://caffe2.ai
- Redistribution of source code must comply with the license and notice disclaimers
- Redistribution in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimers in the documentation and/or other materials provided by the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS “AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE ICT CHINESE ACADEMY OF SCIENCES BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.