AIBench Scenario Framework Guidelines
AIBench scenario framework supports easily build a scenario benchmark. The steps are as follows.
(1) Determine the essential AI and non-AI component benchmarks.
(2) For each component benchmark, find the valid input data from the data input module.
(3) Determine the valid permutation of AI and non-AI components.
(4) Specify the module-related configurations, i.e., input data, execution parameters, Non-AI libraries, and cluster-related configurations, i.e., node, memory, and network information.
(5) Specify the deployment strategy and write the scripts for the automated deployment tool.
(6) Train the AI models of the selected AI component benchmarks using the offline training module, and transfer the trained models to the online inference module.
E-commerce Search Intelligence
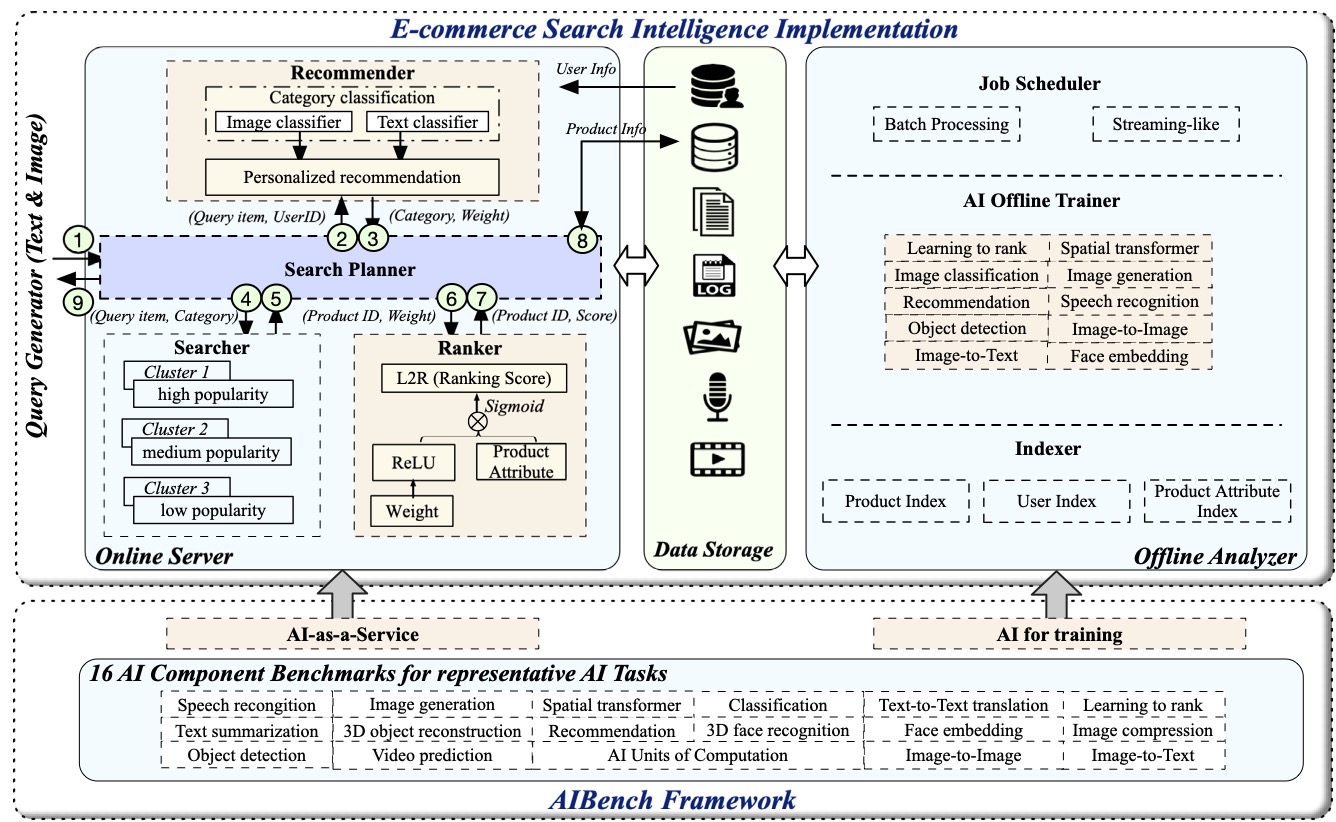
The E-commerce Search Intelligence scenario benchmark consists of four modules: online server, offline analyzer, query generator, and data storage, as shown in Fig. 1. Among them, online server receives the query requests and performs personalized searching and recommendation, integrated with AI inference.
Offline analyzer chooses the appropriate AI algorithm implementations and performs a training stage to generate a learning model. Also, the offline analyzer is responsible to build data indexes to accelerate data access.
Query Generator is to simulate concurrent users and send query requests to Online Server based on a specific configuration. Note that a query item provides either a text or an image to reflect different search habits of a user. The configuration designates the parameters like concurrency, query arriving rate, distribution, user thinking time, and ratio of text items to image items. The configurations simulate different query characteristics and satisfy multiple generation strategies. We implement Query Generator based on JMeter.
The Data Storage module stores all kinds of data. User Database saves all the attributes of the user information. Product Database holds all the attributes of the product information. The logs record the complete query histories. The text data contain the product description text or user comments. The image and video data depict the appearance and usage of a product vividly. The audio data contain the voice search data and voice chat data.
To support scalable cluster deployments, each module is scalable and can be deployed on multiple nodes. Also, a series of data generators are provided to generate E-commerce data with different scales, through setting several parameters, e.g., the number of products and product attribute fields, the number of users and user attribute fields.
Figure 1 E-commerce Search Intelligence Architecture.
(1) Online Server
Online server provides personalized searching and recommendations combining traditional machine learning and deep learning technologies. Online server consists of four submodules including search planer, recommender, searcher, and ranker.
Search Planer is the entrance of online server. It is responsible for receiving the query requests from query generator, and sending the request to the other online components and receiving the return results. We use the Spring Boot framework to implement the search planer.
Recommender is to analyze the query item and provides personalized recommendation, according to the user information obtained from the user database. It first conducts query spelling correction and query rewrite, then it predicts the belonged category of the query item based on a classification model—FastText. Using a deep neural network proposed by Alibaba, the query planer then conducts an inference process and uses the offline trained model to provide personalized recommendation. It returns two vectors—the probability vector of the predicted categories and the user preference score vector of product attribute, such as the user preference for brand, color, etc. We use the Flask Web framework and Nginx to build our recommender for category prediction, and adopt TensorFlow serving to implement online recommendation.
To guarantee scalability and service efficiency, Searcher follows an industry scale architecture. Searcher is deployed on several different, i.e., three clusters, that hold the inverted indexes of product information in memory to guarantee high concurrency and low latency. In view of the click-through rate and purchase rate, the products belong to three categories according to the popularity—high, medium, and low, occupying the proportion of 15%, 50%, and 50%, respectively. Note that the high popularity category is the top 15% popular products chosen from the medium popularity category. The indexes of products with different popularities are stored into different clusters. Given a searching request, the searcher searches these three clusters one by one, until reaching a specific amount. Generally, the cluster that holds low popularity products is rarely searched in a realistic scenario. So for each category, searcher adopts different deployment strategies. The cluster for high popularity contains more nodes and more backups to guarantee the searching efficiency. While the cluster for low popularity deploys the least number of nodes and backups. We use the Elasticsearch to set up and manage the three clusters of searcher.
Ranker uses the weight returned by Recommender as initial weight, and ranks the scores of products through a personalized L2R neural network. The ranker also uses the Elasticsearch to implement product ranking.
(2) Offline Analyzer
Offline analyzer is responsible for training models and building indexes to improve the online serving performance. It consists of three parts—AI trainer, job scheduler, and indexer.
AI trainer is to train models using related data stored in database. To dig the features within product data, e.g., text, image, audio, video, and power the efficiency of online server, the AI trainer chooses ten AI algorithms (component benchmarks) from the AIBench framework currently, including classification for category prediction, recommendation for personalized recommendation, learning to ranking for result scoring and ranking, image-to-text for image caption, image-to-image and image generation for image resolution enhancement, face embedding for face detection within an image, spatial transformer for image rotating and resizing, object detection for detecting video data, speech recognition for audio data recognition.
Job schedule provides two kinds of training mechanisms: batch processing and streaming-like processing. In a realistic scenario, some models need to be updated frequently. For example, when we search an item and click one product showed in the first page, the application will immediately train a new model based on the product that we just clicked, and make new recommendations shown in the second page. Our benchmark implementation considers this situation, and adopts a streaming-like approach to update the model every several seconds. For batch processing, the trainer will update the models every several hours. The indexer is to build indexes for product information. In total, the indexer provides three kinds of indexes, including the inverted indexes with a few fields of products for searching, forward indexes with a few fields for ranking, and forward indexes with a majority of fields for summary generation.
Online Translation Intelligence
Translation Intelligence consists of four subsystems: Online Server, Offline Analyzer, Query Generator, and Data Storage, shown in Fig. 2. Among them, Online Server receives query requests and performs translation. Offline Analyzer chooses the corresponding AI component benchmarks and trains a learning model. Query Generator simulates concurrent users and send text, audio, or image queries to Online Server according to specific configurations. The configuration information is the same with that of E-commerce Intelligence, which is based on JMeter. The Data Storage module stores the query histories, training data and validation data used for the translation of text, audio, and image queries.
Figure 2 Online Translation Intelligence Architecture.
![]()
(1) Online Server
Online Server is responsible for providing translation services. It consists of four modules, including Search Planner, Image Converter, Audio Converter, and Text Translator.
Search Planner receives the query request and determines which modules should be delivered to. The text, audio, and image queries are delivered to Text Translator, Audio Converter, and Image Converter, respectively. Search Planner uses the Spring Boot framework.
Image Converter receives an image query and extracts the text information within the image. It first loads the image data and performs image preprocessing through a BASE64 image encoder, since a RESTful API requires binary inputs to be encoded as Base64. Then it converts the image into text using an offline trained model–optical character recognition (OCR). After that, the extracted text information is sent to Text Translator for text translation. We reuse the Image-to-Text component.
Audio Converter receives an audio query and performs speech recognition to recognize the text information within an audio. It first loads the audio data and performs audio preprocessing, which converts an input audio into a WAV format with 16KHz. And then the Speech Recognition component is reused to recognize the text information.
Text Translator performs text-to-text translations. It receives text queries directly from the Search Planner or the converted text data from Image Converter and Audio Converter. We reuse the Textto-Text Translation component. We use TensorFlow Serving to provide OCR, speech recognition, and translation services.
(2) Offline Analyzer
Offline Analyzer is responsible for job scheduling, and AI model training and updating. Among them, Job Scheduler includes batch processing and streaming-like processing, which are the same like that of E-commerce Intelligence. AI Offline Trainer is to train learning models or perform real-time model updates for online inference. For Translation Intelligence, AI Offline Trainer chooses three AI components from the AIBench framework, including Speech Recognition, Image-to-Text (OCR), and Text-to-Text translation.