The specification of Edge AIBench is available now. BenchCouncil Edge AIBench uses terminology and metrics that are similar to other BenchCouncil benchmarks, originated by the BenchCouncil or others. Such similarity in terminology does not in any way imply that Edge AIBench results are comparable to other benchmarks. The only benchmark results comparable to Edge AIBench are other Edge AIBench results in conformance with the same revision.
Methodology
Edge AIBench follows the PRDAERS benchmarking rules and methodology presented by BenchCouncil. The PRDAERS is the abbreviation of paper-and-pencil, relevant, diversity, abstractions, evaluation metrics and methodology, repeatable, and scaleable.Figure 1 presents the construction methodology of Edge AIBench.
Firstly, the typical scenarios are extracted to present the numerous edge AI scenarios, and then the primary layers with micro, component and application benchmarks are extracted. What’s more, the heterogeneous representative real-world datasets are chosen as the dataset.
Paper-and-pencil Approach: Edge AIBench can be specified only algorithmically in a paper-andpencil approach. This benchmark specification is proposed firstly and reasonably divorced from individual implementations. In general, Edge AIBench defines a problem domain in a high-level language.
Relevant: Edge AIBench is domain-specific in edge computing and can be distinguished between different contexts. And in the other hand, Edge AIBench is simplified and distillated of the real-world application. It abstracts the typical scenario and application.
Diversity and Representatives: Modern workloads show significant diversity in workload behavior with no single silverbullet application to optimize. Consequently, diverse workloads and datasets should be included to exhibit the range of behavior of the target applications. Edge AIBench focuses on various edge AI problem domains and tasks.
Abstractions: Edge AIBench contains different levels of abstractionsmicro, component, and endto-end application benchmarks. For comprehensiveness and reality, Edge AIBench models a real-world application, while for portability, the benchmark should be light-weight that can be portable across different systems and architectures. Thus, the benchmark should provide a framework that collectively runs as a end-to-end application and individually runs as a micro or component benchmark.
Evaluation Metrics and Methodology: The performance number of Edge AIBench is simple, linear, orthogonal, and monotonic. Meanwhile, it is domain relevant. The metrics chosen by Edge AIBench is relevant to edge computing AI scenarios, such as accuracy, layency, and network metrics.
Repeatable, Reliable, and Reproducible: Since many egde computing deep learning workloads are intrinsically approximate and stochastic, allowing multiple different but equally valid solutions[14], it will raise serious challenges for Edge AIBench.
Scaleable: Edge AIBench should be scaleable. Thus, the benchmark users can scale up the problem size.
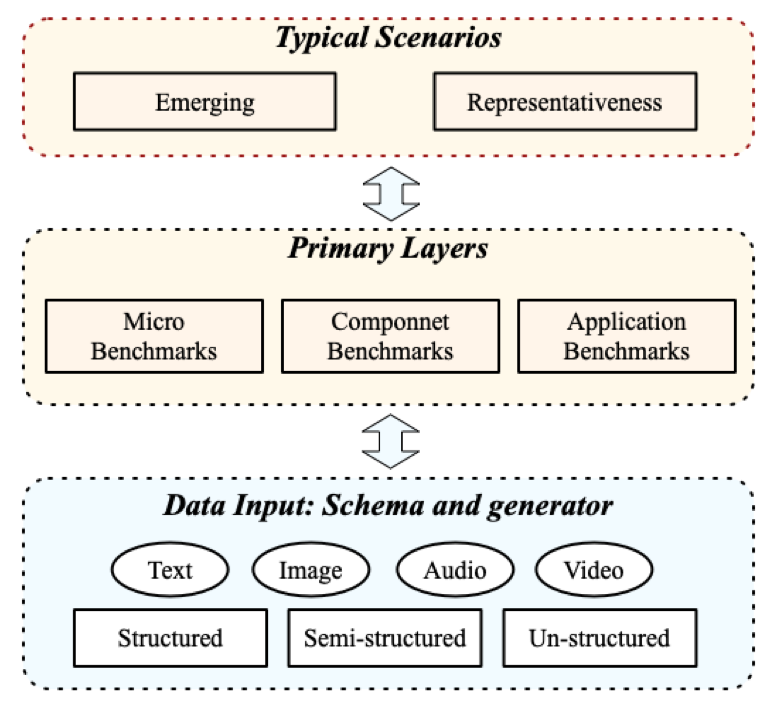
Figure 1 Methodology of Edge AIBench
Benchmark Problem Domains
1. ICU Patient Monitor.
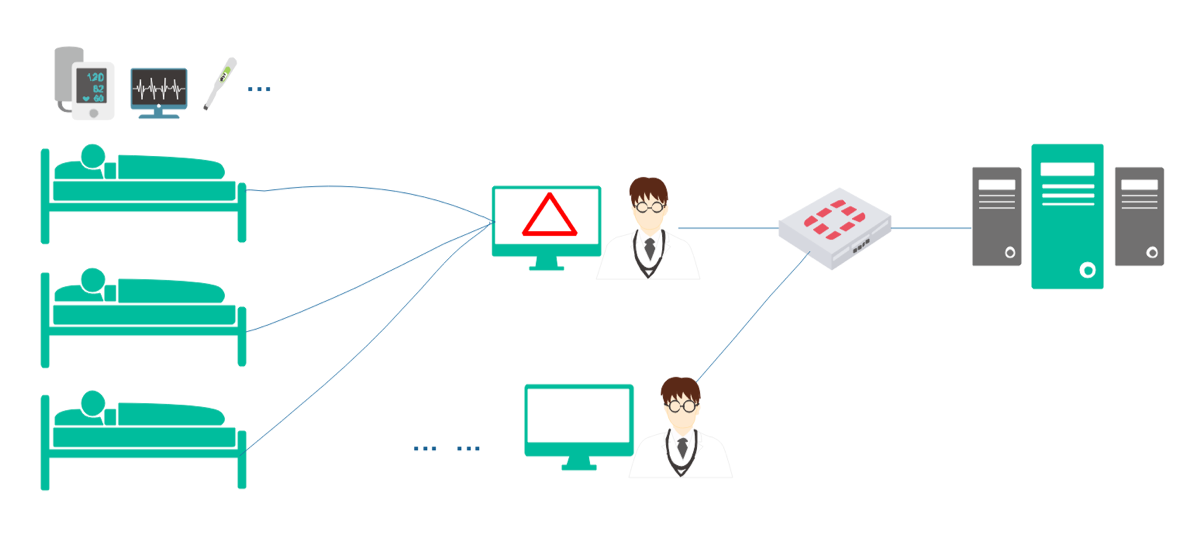
Figure 2 ICU Patient Monitor Scenario
Application benchmarks:
1. Death Prediction
2. Decompensation Predic-tion
3. Phenotype Classification
Datasets:
MIMIC-III
2. Survelliance Camera
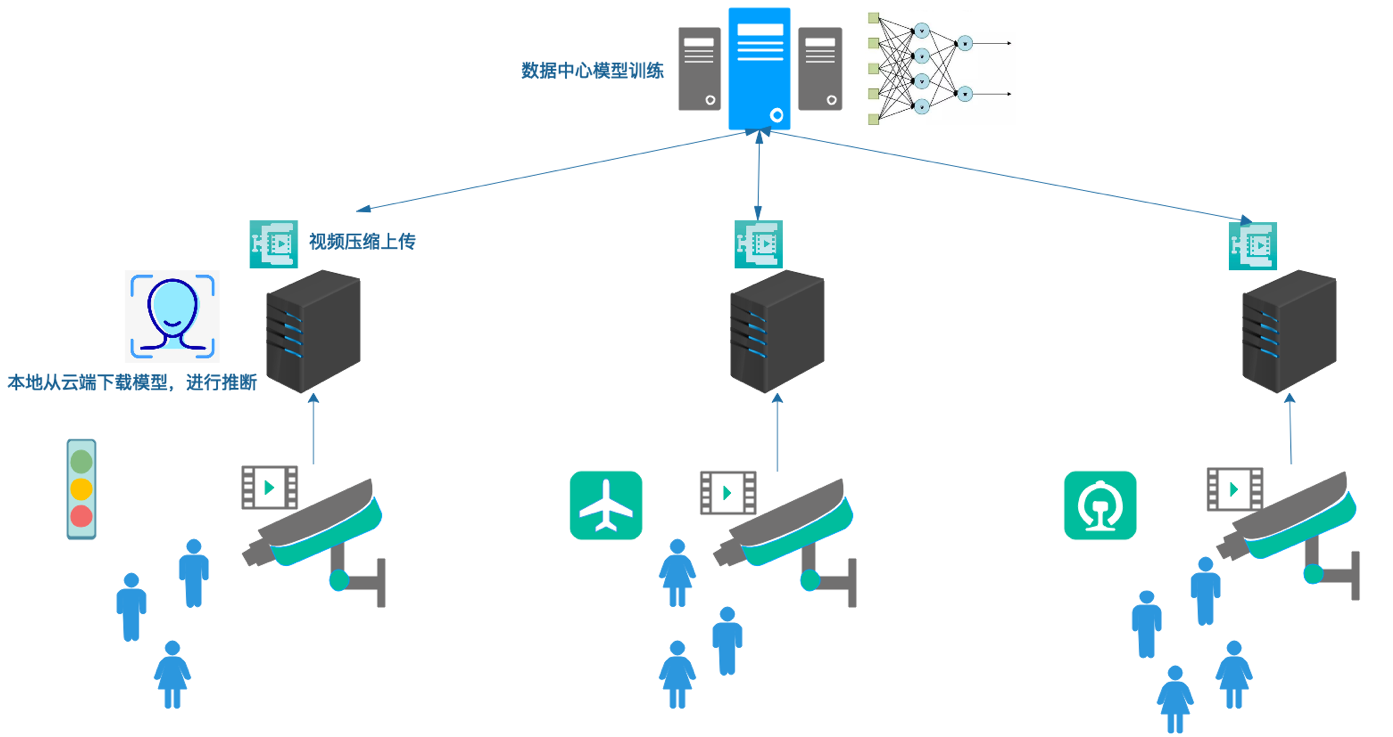
Figure 3 Survelliance Camera Scenario
Application benchmarks:
1. Person Re-identification
2. Action Detection
Datasets:
Market-1501 dataset
UCF101
3. Smart Home
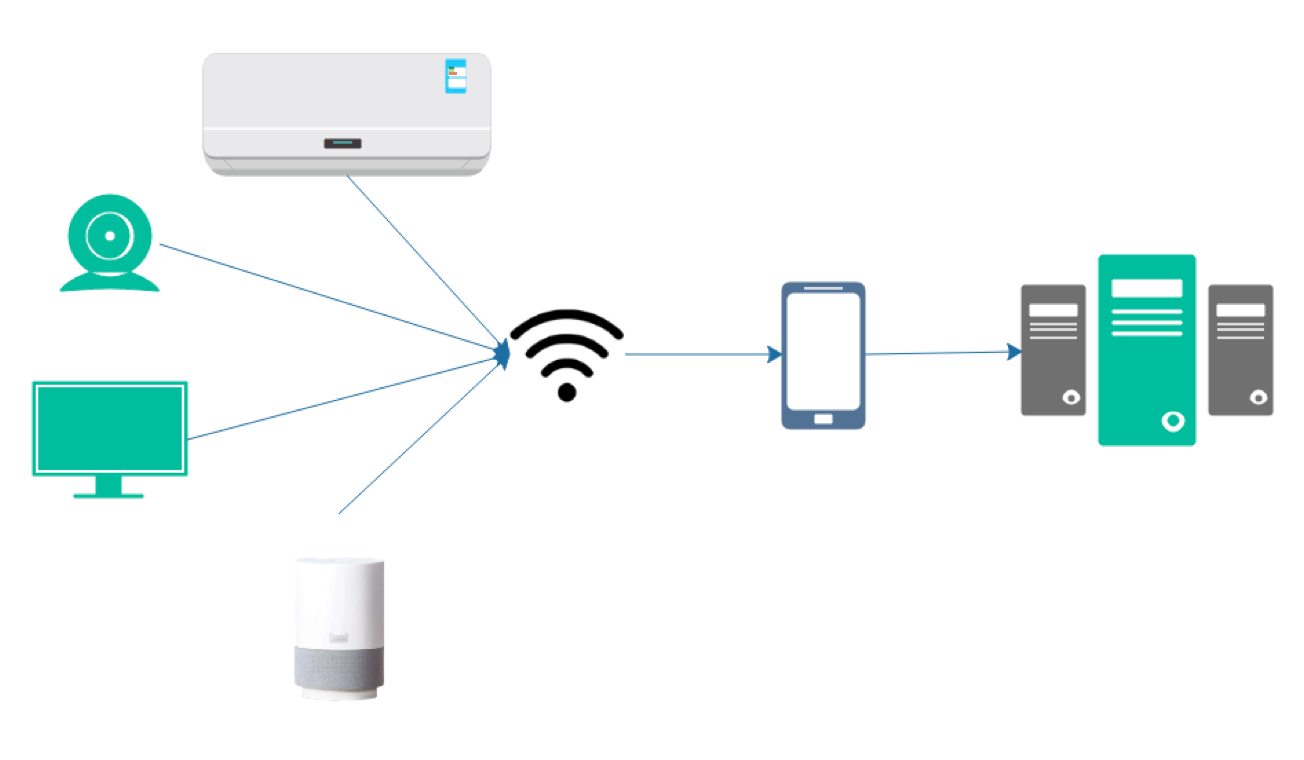
Figure 4 Smart Home Scenario
Application benchmarks:
1. Speech Recognition
2. Face Recognition
Datasets:
LibriSpeech
LFW
CASIA-Webface
4. Autonomous Vehicle
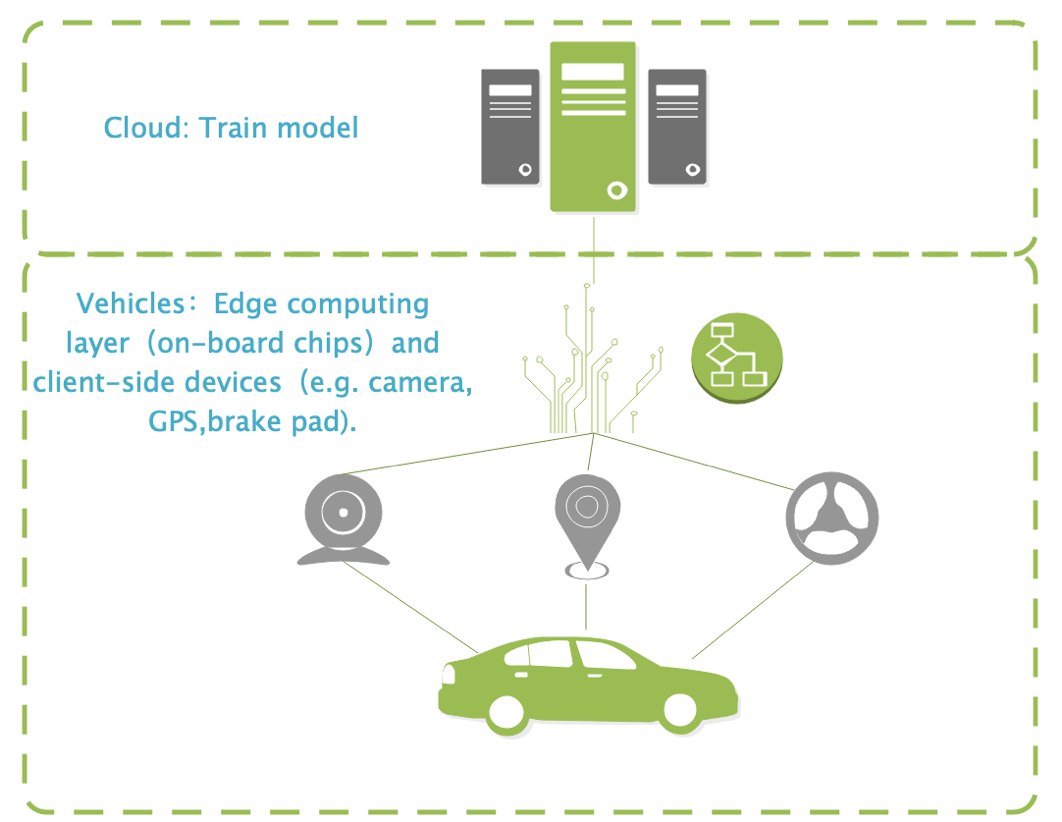
Figure 5 Autonomous Vehicle Scenario
Application benchmarks:
1. Lane Keeping
2. Road Sign Recognition
Datasets:
Tusimple dataset
CULane
German Traffic Sign Recognition Benchmark dataset