Summary
The AI advancements have brought breakthroughs in processing images, video, speech, and audio, and hence boost industry-scale deployments of massive AI algorithms, systems, and architectures. The benchmarks accelerate the process, as they provide not only the design inputs, but also the evaluation methodology and metrics. Unfortunately, there are many factors mutually aggravating the challenges of AI benchmarking.
First, the prohibitive cost of training a state-of-the-art AI model raises serious benchmarking challenges. For running an AI component benchmark–that is to train an AI model to achieve a state-of-the-art quality target–some mixed-precision optimizations immediately improve traditional performance metrics like throughput, while adversely affect the quality of the final model, which can only be observed by running an entire training session. Running an entire training session on a small-scale system is prohibitively costly, often taking several weeks. The architecture community heavily relies upon simulations with slowdowns varying wildly from 10X to 1000X, which further exaggerates the challenge.
Second, there are conflicting requirements (affordable vs. comprehensive) in different stages of industry-standard benchmarking, which further aggravates the challenges. On one hand, for reducing the portability cost, affordable AI benchmarks are needed for earlier-stage evaluations of a new architecture or system for validation. Meanwhile, for promoting its adoption, affordable benchmarks are also necessary to provide valuable performance implications in ranking the off-the-shelf systems or architectures.
On the other hand, later-stage evaluations or purchasing off-the-shelf systems needs detailed evalua-tions using comprehensive benchmarks to avoid benchmarketing, and using a few AI component benchmarks alone may lead to misleading or unfair conclusions in the other stages.
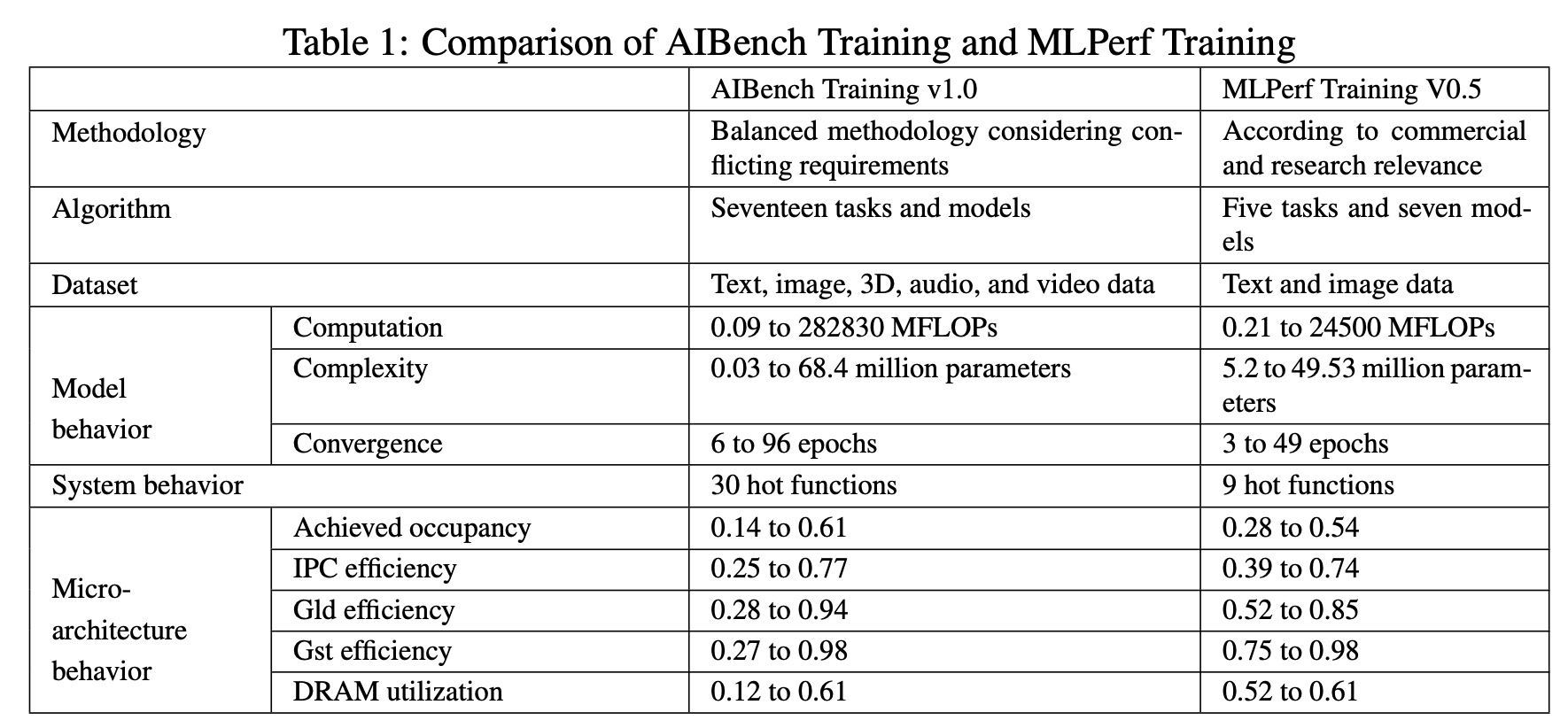
To tackle the above challenges, we present a balanced AI benchmarking methodology for meeting the conflicting requirements of different stages. On one hand, with seventeen prominent industry partners, we identify and include seventeen representative AI tasks from the important domain–Internet Services to guarantee the representativeness and diversity of the benchmarks. On the other hand, we select a minimum benchmark subset (three tasks) for affordability according to the criteria: diversity of model complexity, computational cost, convergence rate, repeatability, and having widely-accepted metrics or not. Table 1 summarizes the differences of AIBench Training V1.0 against MLPerf Training V0.5.
The Methodology
Our balanced AI benchmarking methodology consists of five essential parts as follows.
- Performing a detailed survey of the most important domain rather than a rough survey of a variety of domains.
As it is impossible to investigate all AI domains, we single out the important AI domain–Internet services for the detailed survey with seventeen prominent industry partners. - Include as most as possible representative benchmarks.
We believe the prohibitive cost of training a model to a state-of-the-art quality cannot justify including only a few AI benchmarks. Instead, using only a few AI component benchmarks may lead to error-prone design: over-optimization for some specific workloads or benchmarketing.
For Internet services, we identify and include as most as possible representative AI tasks, models and data sets into the benchmark suite, so as to guarantee the representativeness and diversity of the benchmarks.
This strategy is also witnessed by the past successful benchmark practice. Actually, the cost of execution time for other benchmarks like HPC, SPECCPU on simulators, is also prohibitively costly. However, the representativeness and coverage of a widely accepted benchmark suite are paramount important. For example, SPECCPU 2017 contains 43 benchmarks. The other examples include PARSEC3.0 (30), TPC-DS (99). -
Keep the benchmark subset to a minimum.
We choose a minimum AI component benchmark subset according to the criteria: diversity of model complexity, computational cost, convergence rate, repeatability, and having the widely-accepted metrics or not. Meanwhile, we quantify the performance relationships between the full benchmark suite and its subset.
Using the subset for ranking is also witnessed by the past practice. For example, Top500-a super computer ranking–only reports HPL and HPCG–two benchmarks out of 20+ representative HPC benchmarks like HPCC, NPB. -
Consider the comprehensive benchmarks and its subset as two indispensable parts.
Different stages have conflicting benchmarking requirements. The initial design inputs to a new system/architecture need comprehensive workload characterization. For earlier-stage evaluations of a new system or architecture, which even adopts simulation-based methods, heavy benchmarking is a big burden, thus, concise, portable, and lightweight benchmarks are of great significance. While later-stage evaluations of a new architecture or system or purchasing an commercial off-the-shelf ones needs detailed evaluation using comprehensive benchmarks to avoid error-prone design or benchmarketing.
For initial design inputs, we perform detailed workload characterization. For later-stage evaluations of or purchasing a new system/architecture, we run the full benchmarks or selectively run some benchmarks to quickly locate the bottlenecks.
For earlier-stage evaluations of a new system/architecture or ranking commercial off-the-shelf systems/architectures, we run an affordable subset. -
Layered Benchmarking Rules.
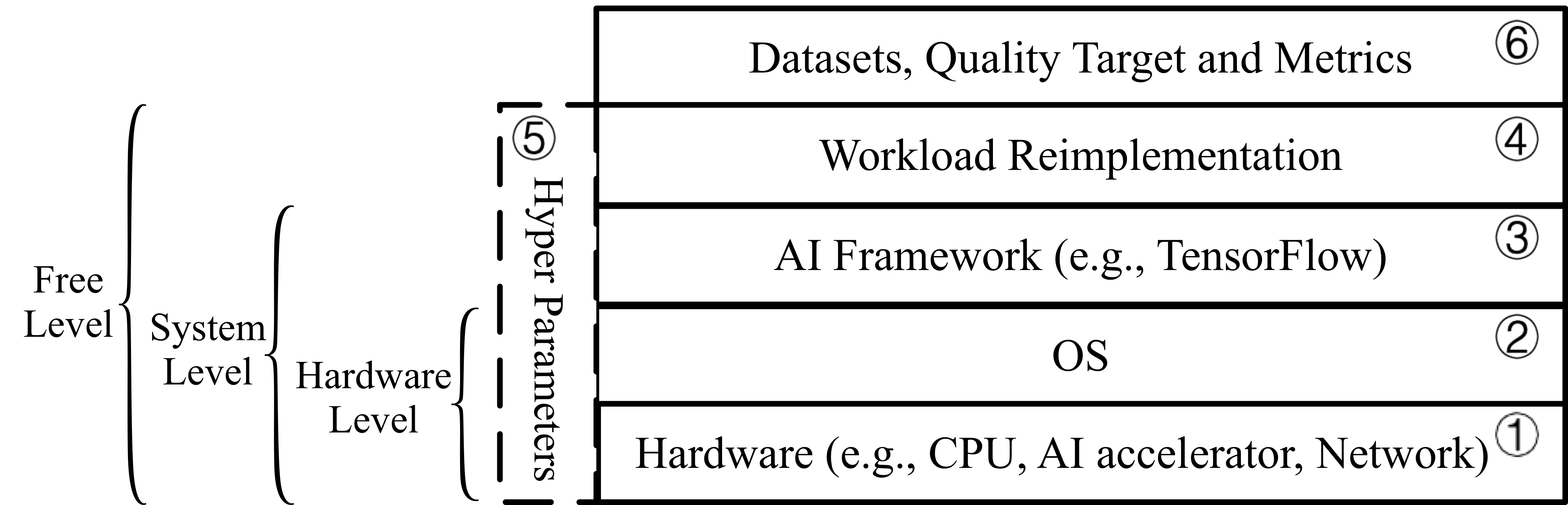
We define six benchmarking layers and corresponding rules, as illustrated in Fig. 2. In the hardware layer, the hardware configurations are allowed to be adjusted. OS layer represents the OS configurations or compiler options can be optimized. AI Framework layer means the AI framework can be changed. Workload re-implementation layer indicates that the re-implementation is allowed, however, it should be mathematical equivalence with the reference implementation. Hyper parameter layer defines the rules for hyper-parameter settings, including batchsize, learning rate, and the other hyper-parameters. To be specific, batchsize is allowed to be changed so as to fully utilize the hardware resources. Datasets and metrics layer specify the data input and evaluation metric, and cannot be modified. According to the above six layers, we define three-level benchmarking, including hardware, system, and free levels, as illustrated in Fig. 2.
- Hardware Level. This level allows the modifications of hardware, OS, and hyper-parameter layers, with the other layers unchanged.
- System Level. This level allows the modifications of hardware, OS, AI framework, and hyper-parameter layers, while the others are fixed. Note that for both hardware level and system level, only batchsize and learning rate are allowed to be changed, while the other hyper-parameters need to be the same with the reference implementation.
- Free Level. This level allows the modifications of all layers except for the datasets and metrics layer. Note that all the hyper-parameters are allowed to be changed.
Contributors
Prof. Jianfeng Zhan, ICT, Chinese Academy of Sciences, and BenchCouncil
Dr. Wanling Gao, ICT, Chinese Academy of Sciences
Fei Tang, ICT, Chinese Academy of Sciences
Dr. Lei Wang, ICT, Chinese Academy of Sciences
Xu Wen, ICT, Chinese Academy of Sciences
Chuanxin Lan, ICT, Chinese Academy of Sciences
Chunjie Luo, ICT, Chinese Academy of Sciences
Yunyou Huang, ICT, Chinese Academy of Sciences
Dr. Chen Zheng, ICT, Chinese Academy of Sciences, and BenchCouncil
Dr. Zheng Cao, Alibaba
Hainan Ye, Beijing Academy of Frontier Sciences and BenchCouncil
Jiahui Dai, Beijing Academy of Frontier Sciences and BenchCouncil
Daoyi Zheng, Baidu
Haoning Tang, Tencent
Kunlin Zhan, 58.com
Biao Wang, NetEase
Defei Kong, ByteDance
Tong Wu, China National Institute of Metrology
Minghe Yu, Zhihu
Chongkang Tan, Lenovo
Huan Li, Paypal
Dr. Xinhui Tian, Moqi
Yatao Li, Microsoft Research Asia
Dr. Gang Lu, Huawei
Junchao Shao, JD.com
Zhenyu Wang, CloudTa
Xiaoyu Wang, Intellifusion
Ranking
AIBench results are released.
License
AIBench is available for researchers interested in AI. Software components of AIBench are all available as open-source software and governed by their own licensing terms. Researchers intending to use AIBench are required to fully understand and abide by the licensing terms of the various components. AIBench is open-source under the Apache License, Version 2.0. Please use all files in compliance with the License. Our AIBench Software components are all available as open-source software and governed by their own licensing terms. If you want to use our AIBench you must understand and comply with their licenses. Software developed externally (not by AIBench group)
- TensorFlow: https://www.tensorflow.org
- PyTorch: https://pytorch.org/
- Caffe2: http://caffe2.ai
- Redistribution of source code must comply with the license and notice disclaimers
- Redistribution in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimers in the documentation and/or other materials provided by the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS “AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE ICT CHINESE ACADEMY OF SCIENCES BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.