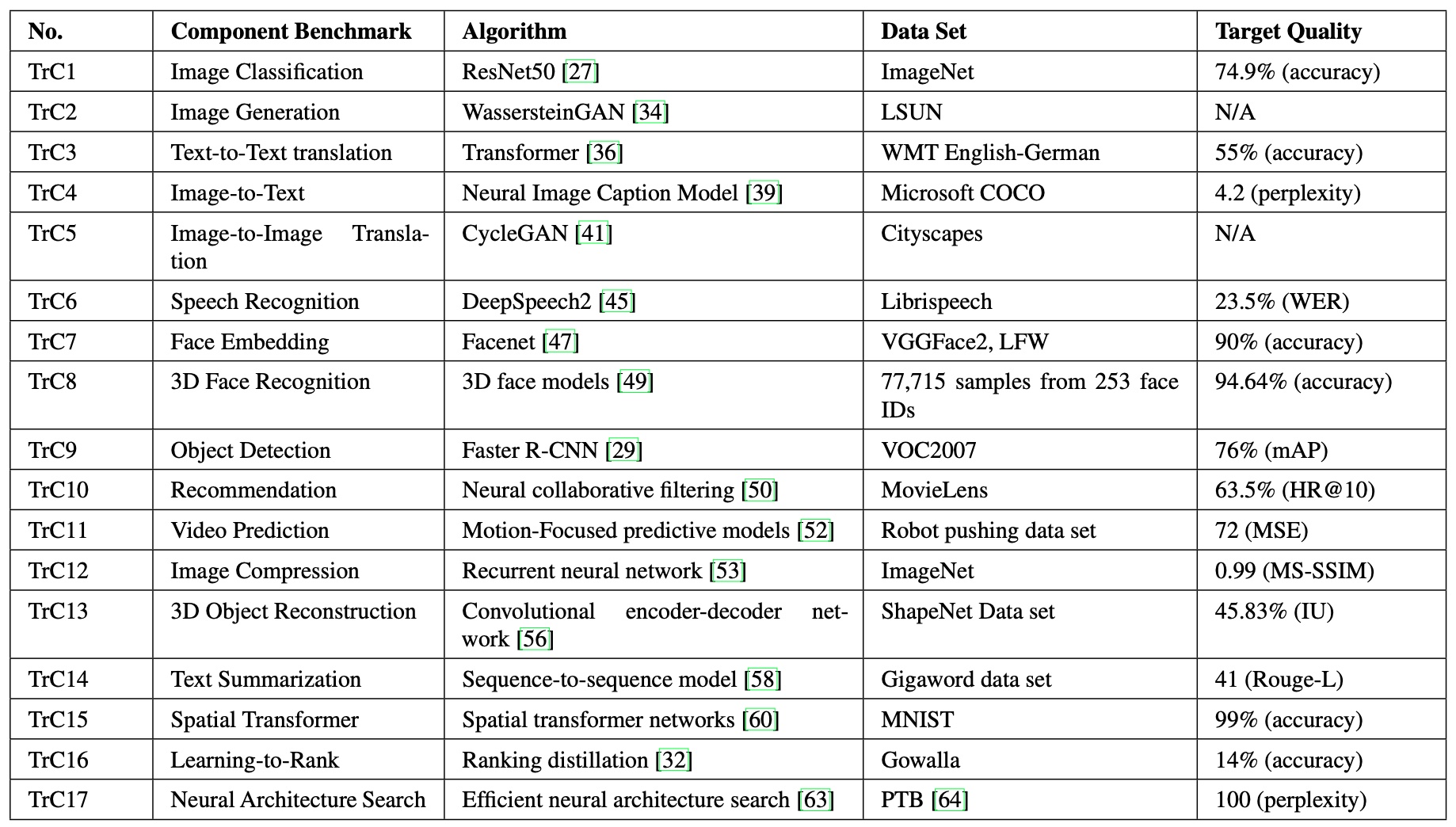
AIBench Training
-
Image Classification
Image classification is a fundamental AI task to classify an image into multiple categories, which is widely used in many competitions, such as the Large Scale Visual Recognition Challenge.
ResNet-50: ResNet-50 is a milestone model which exerts the ability of AI to classify images and exceeds the ability of humans initially. It is a convolutional neural network with 50 layers.
ImageNet Dataset: This dataset is one of the world’s largest image database, containing more than 14 million images, and the data size is more than 100 GB. Moreover, it is the most popular dataset in computer vision and is used for many tasks like image classification and object detection.
Reference Quality: The reference implementation on the ImageNet dataset achieves Top-1 accuracy 74.9%.
-
Object Detection
Object detection aims to find objects of certain target classes with precise localization in a given image. And like image classification, object detection is one of the most important tasks in computer vision.
Faster R-CNN Model: For object detection, we use the Faster R-CNN model, with the backbone network of ResNet-101 to extract the features of an input image. This is a classical model for object detection task and is the cornerstone of many other models such as Mask R-CNN.
VOC2007: This dataset is one of the most widely used datasets in object detection. It has 9,963 images, containing 24,640 annotated objects. Each image has an annotation file giving a bounding box and object class label for each object in one of the twenty classes present in the image.
-
Learning-to-Rank
Learning-to-Rank is to train models for ranking tasks using machine learning methods. It is significant for industry for search, recommendation, and advertising, with a little optimization bringing in huge revenues.
Ranking Distillation Model: Ranking distillation is a representative model for improving ranking performance especially inference without loss of precision. It is an important model that is used by our industry partners to shorten the latency and improve the service quality. It is a technique that uses knowledge distillation to train a smaller student model for ranking under the supervision of a larger teacher model, and this student model has similar performance to the teacher model but has better online inference performance.
Gowalla Dataset: This dataset is a representative social network data, which is a part of Stanford Network Analysis Project. It contains the locations shared by users and user relationship networks, including 196591 nodes, 950327 edges, and 6442890 location sharing records.
Reference Quality: The target accuracy of the model is 14% on the Gowalla dataset.
-
Image Generation
Image generation is to generate similar images with the input image. Image generation is an emerging and hotspot topic in academia and is promising in areas such as design and gaming.
Wasserstein Generative Adversarial Networks Model: This model is one of the most famous GAN-based models, which uses adversarial generation networks to solve image generation problems. It consists of a generator and a discriminator, including 4-layer RELU-MLP with 512 hidden units.
LSUN Dataset: This task uses the LSUN-Bedrooms dataset. This dataset is a large markup dataset containing 10 scenes and 20 object classes, and is primarily applied to the task of scene understanding.
Reference Quality: This task has no widely accepted evaluation metric. We use the estimated Earth-Mover (EM) distance as loss function in training, which needs to reach 0.5 ± 0.005.
-
Text-to-Text Translation
Text-to-Text translation is to translate a sequence of words into another language and is one of the most representative tasks in nature language processing.
Transformer: Transformer is the classical model for text translation and is the basis for the subsequent Bert model. It is combined with self-attention and Feed Forward Neural Network.
WMT English-German Dataset: The training dataset is the WMT’14 English-German data, which has 4.5 million sentence pairs.
Reference Quality: The target accuracy is 55%.
-
Image-to-Text
Image-to-text is to generate a description for each image automatically. This is an integrated problem combining computer vision, natural language processing, and machine learning.
Neural Image Caption Model: This model consists of a vision convolution neural network (CNN) followed by a language generating recurrent neural network (RNN).
MSCOCO 2014 Dataset: This dataset is a widely used image dataset. And The dataset has more than 82,000 images with caption annotations, and the testing set is separated from the training set.
Reference Quality: The model achieves 4.2 perplexity on the MSCOCO 2014 dataset.
-
Image-to-Image Translation
Image-to-image translation is to learn image mapping of two different domains and can be used for style conversion, object conversion, seasonal conversion and photo enhancement, which is an important component for industrial applications.
CycleGAN Model: CycleGAN is another widely used GAN-based model, which uses the adversarial generation network to do Image-to-Image Transformation and has two generators and two discriminators. Following, our generator adopts the network structure in, and the discriminator adopts 70x70 PatchGANs.
Cityscapes Dataset: The Cityscapes dataset contains a diverse set of stereo video sequences recorded from 50 different cities and is a large-scale dataset for Image-to-Image problem.
Reference Quality: This task has no widely accepted evaluation metric. We adopt per-pixel accuracy (0.52 ± 0.005), per-class accuracy (0.17 ± 0.001), and Class IOU (0.11 ± 0.001) referring to the Cityscapes benchmark.
-
Speech Recognition
Speech recognition is the most important task in audio processing and it is to recognize a speech audio and translate it into a text.
DeepSpeech2 Model: DeepSpeech2 is a milestone model in speech recognition. And the model is a recurrent neural network (RNN) with one or more convolutional input layers, followed by multiple recurrent layers and one fully connected layer before a softmax layer.
LibriSpeech Dataset: LibriSpeech is the most representative audio dataset and it contains 1000 hours of speech sampled at 16 kHz.
Reference Quality: The word error rate (WER) of the reference implementation of DeepSpeech2 model on LibriSpeech validation data is 23.5%.
-
Face Embedding
Face embedding is to verify a face by learning an embedding into the Euclidean space and this can be used as face recognition, which is an important area. This task uses a 2D face dataset.
FaceNet: FaceNet model is a representative model and it is based on the GoogleNet style Inception model, which has about 24 million parameters.
VGGFace2 Dataset: This dataset has large variations in pose, age, illumination, ethnicity and profession, including 9000+ identities, and 3.3 million+ faces.
Reference Quality: The target quality is an accuracy of 90%.
-
3D Face Recognition
3D face recognition performs identification of 3D face images, which is an important task in developing, and has high requirements of reliability and stability.
3D Face Model: The model uses ResNet-50 network as backbone network and adjusts the first convolutional layer and the fully connect layer so that RGB-D images can be fed into the RGB-D ResNet-50 model.
Intellifusion Dataset: The dataset is a RGB-D dataset, provided by Intellifusion.
Reference Quality: The reference implementation achieves an accuracy of 94.64% on the Intellifusion dataset.
-
Recommendation
This task is essential in industry and is widely used for advertisement recommendation, community recommendation, and etc.
Neural collaborative filtering (CF): CF is a fundamental algorithm for recommendation. Neural CF is a probabilistic approach using Gaussian assumptions on the known data and the factor matrices.
MovieLens Dataset: The MovieLens is a real-world movie ratings dataset from IMDB (the world’s most popular and authoritative source for movie), The Movie DataBase, etc. The 100K movie ratings dataset contains 100,000 ratings from 1000 users on 1700 movies.
Reference Quality: The quality metric is HR@10, which means whether the correct item is on the top-10 list. The target quality is 63.5% HR@10.
-
Video Prediction
Video prediction is to predict how its actions affect objects in its environment, which is a representative vido processing task.
Motion-Focused Predictive Model: This model predicts how to transform the last image into the next image.
Robot Pushing Dataset: This dataset contains 59,000 robot interactions involving pushing motions.
Reference Quality: This task achieves 72 MSE on the test data.
-
Image Compression
Image compression aims to reduce the cost for storage or transmission. And bringing deep learning to image compression is an innovative work.
Recurrent Neural Network: This model is representative of the RNN network, and it consists of a recurrent neural network (RNN)-based encoder and decoder, a binarizer, and a neural network for entropy coding.
ImageNet Dataset: The dataset used for this task is the same with that of Image Classification.
Reference Quality: The metric is 0.99 MS-SSIM (Multi-Scale-Structural Similarity Index).
-
3D Object Reconstruction
3D object reconstruction is to capture the shape and appearance of a real object, which is a core technology of a wide variety of fields like computer graphics and virtual reality.
Convolutional Encoder-decoder Network: This model combines image encoder, volume decoder, and perspective transformer.
ShapeNet Dataset: ShapeNetCore contains about 51,300 unique 3D models from 55 common object categories.
Reference Quality: The metric is the average IU (intersection-over-union) score. The target average IU is 45.83% on ShapeNetCore.
-
Text Summarization
Text summarization is a task of generating a headline or a short summary and is a important task in nature language processing like translation.
Sequence-to-sequence Model: This model consists of an off-the-shelf attentional encoder- decoder RNN.
Gigaword Dataset: The dataset contains about 3.8M training examples, and 400K validation and test examples.
Reference Quality: The model achieves 41 Rouge-L on the Gigaword dataset.
-
Spatial Transformer
Spatial Transformer is to provide spatial transformation capabilities and can be used to process distorted and deformed objects to improve the accuracy of other vision tasks, such as image classification and object detection.
Spatial Transformer Network: The model includes a localisation network, a grid generator, a sampler.
MINST Dataset: The MNIST dataset consists of 60,000 training images and 10,000 test images. Reference Quality: This task achieves an accuracy of 99%.
-
Neural Architecture Search
Neural network search is to automatically design neural networks and has already achieved great success in image classification and language model.
Neural Architecture Search: Neural Architecture Search is to maximize the accuracy of the searched neural network.
Reinforcement learning: This model finds efficient neural networks by sharing parameters in child models to find a optimal neural architecture.
PTB Dataset: The dataset contains 2,499 stories from a three-year Wall Street Journal collection of 98,732 stories for syntactic annotation.
Reference Quality: The target quality is 100 perplexity.